- Топ-10 причин падения серверов
- Как понять почему упал сервер не подключая к нему монитор и клавиатуру?
- Лёг сервер
- Какие попытки я предпринял, что бы поиметь «минимум гемороя» с серваком:
- Быстрые пути решения данной проблеммы с восстановлением сервака:
- Когда у вас лёг сервер:
- Пять шагов к спасению Linux-сервера, который рухнул
- Поиск и устранение неполадок: раньше и теперь
- Шаг первый. Проверка аппаратного обеспечения
- Шаг второй. Поиск истинного источника проблемы
- Шаг третий. Использование команды top
- Шаг четвёртый. Проверка дискового пространства
- Шаг пятый. Проверка логов
- Итоги
Топ-10 причин падения серверов
— Ты чего такой грустный?
— Да вот сервер вчера «упал».
— Ну да, ты что его до сих пор не «поднял»?
— Поднял, но он со стола упал.
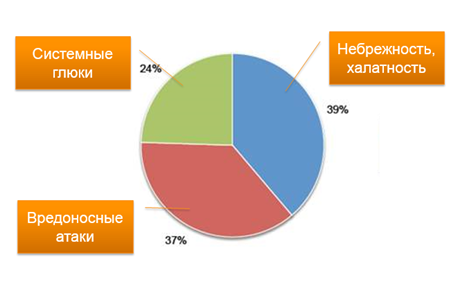
По статистике, 60% «косяков» лежит на плечах сотрудников компании. Из них основной причиной является небрежность или халатность (39%), а 43% были вызваны успешными вредоносными атаками, не требующими глубоких знаний и навыков. Более подробно об этом я уже писал об этом в предыдущей статье, а сегодня я хочу предложить очередной чарт: «Топ 10 — Как падают серверы?». Или почему «падают»?
10 место. Резервное копирование. Системные администраторы бывают двух видов: которые делают резервные копии и которые пока не делают резервные копии. Бывает еще и третий вид, но очень редкий: системные администраторы, которые проверяют свои резервные копии. На них вся надежда.
9 место. Источники бесперебойного питания. Стандартная ситуация: погас свет, а вместе с ним «погас» и сервер баз данных. Свет появился, а сервер в сети — нет. А вместе с ним не появились и 200 терабайт информации, нажитой непосильным трудом и упорством. Компания приостановилась на несколько дней, а вместе с ней приостановилось и действие трудового договора системного администратора. А казалось бы, поменяй батарейки, настрой автоматическое отключение…
8 место. Оборудование. Вместо серверных платформ используются обычные рабочие станции. Бывали случаи, когда база 1С лежала у бухгалтера на рабочем компьютере на диске D, и даже резервных копий никто не делал! Вопиющая смелость!
7 место. Использование нелицензионного ПО. Был случай, когда один товарищ пытался убедить меня в то, что весть его софт абсолютно лицензионный. Дабы подтвердить свои слова, мне был продемонстрирован лицензионный компакт-диск со всем софтом, купленный в фирменной палатке на Ждановичах. Чек прилагался.
6 место. Плановые замены HDD. Примерно раз в два-три месяца слышу новую историю про рассыпавшийся RAID. Для серверных винчестеров ресурс составляет не более 4 лет. Еще одной частой ошибкой является использование дешевых, не серверных винчестеров, что также весьма чревато. Еще я рекомендую при покупке нового оборудования закупать парочку винчестеров в запас, на всякий пожарный.
5 место. Запуск нескольких сервисов на одном сервере. Говорят, системные администраторы не смешиваю. Все они смешивают! Особенно любят администраторы смешивать контроллеры домена с чем-нибудь еще, например, с MS SQL и с 1C, файловым сервером, прокси-сервером и др. Лет 5 назад это не вызвало бы больших нареканий, но сегодня нравы поменялись, смешивать как минимум, неприлично, как максимум, небезопасно.
4 место. Встроенная учетная запись администратора. Как взломать сервер: берем шару и подбираем пароль к встроенной учетной записи администратора. Если пароль состоит из 4 цифр – пара минут, и сервер наш! А всего-то нужно было учетную запись отключить, а еще лучше и переименовать, да через групповые политики.
3 место. Мониторинг. Что такое мониторинг? Это вовсе не зайти раз в неделю\месяц\год в консоли логи посмотреть. Мониторинг — это когда тебе приходит уведомление, что что-то не так, задолго до первого звонка пользователя. В идеале, пользователь вообще не должен успеть позвонить. К сожалению, у нас все больше через консоль.
2 место. Брандмауэр. Какими бы крепкими ни были стены города, они не защитят жителей от больного чумой внутри периметра. Конечно, все дома в городе забором не обнесешь, а вот улочку с серверами обгородить вполне возможно, более того, сисадмины могут сделать это бесплатно и быстро, а если повезет, то и качественно.
1 место. Всемогущий Administrator. Нужно попасть на сервер, запустить сервис MS SQL, сделать бэкап, установить тоталкомандер пользователю, залогиниться на свой комп – бесстрашный domain\Administrator может все! У него сложный пароль – P@ssword — который знает всего человек 10! Он не боится вирусов, которые могут расползаться по сети от его имени! Он может все и не боится ничего!
В очередной раз мы видим, как данные статистики сходятся с жизненными реалиями. А как дела обстоят у вас?
Андрей Махнач
руководитель отдела инфраструктурных решений СООО «ДПА»
Источник
Как понять почему упал сервер не подключая к нему монитор и клавиатуру?
Так бывает что сервер зависает, но к нему не подключена ни клавиатура, ни монитор.
У меня нет лишнего монитора, и обнаружив, что сервер не отвечает по сети,
снимать монитор с моего компьютера и подключать к серверу в кладовке нет никакого желания и сил.
В Linux есть такая возможность ядра как Netconsole.
Netconsole позволяет послать сообщения от ядра на удаленный компьютер.
Для настройки netconsole нужен другой (постоянно включенный) компьютер который примет сообщение по сети.
Проверено на Ubuntu 10.04
На сервере который отлаживаем выполняем:
1. В /etc/modules добавляем netconsole
2. В /etc/modprobe.d/netconsole.conf пишем
options netconsole netconsole=SRCPORT@SRCHOST/eth0,DSTPORT@DSTHOST/DSTMAC
Где SRCPORT и SRCHOST соответственно порт и IP адрес сервера который отлаживаем.
А DSTPORT и DSTHOST порт и IP адрес сервера который будет принимать сообщения.
DSTMAC — это MAC адрес сервера который будет принимать сообщения ЕСЛИ он в той же сети. Если он за роутером или где нибудь в интернете, то нужно указывать MAC адрес ближайшего роутера (Gateway).
Должно получится чтото типа
options netconsole netconsole=6666@192.168.1.2/eth0,6666@192.168.1.3/e0:91:f5:7d:e6:38
На сервере который будет принимать сообщения.
Нам нужно как то запустить программу которая будет слушать UDP порт DSTPORT и куда-либо записывать сообшения.
Самый просто способ — запустить netcat который будет выдавать на экран все что приходит на порт. Для того чтобы после закрытия окна данная программа не прекратила работать, можно запустить ее в screen.
1. Запускаем screen
screen -U -D -RR
2. Запускаем в окне netcat
netcat -l -u DSTHOST DSTPORT
Как понять что все работает?
Можно подождать какого нибудь события, но как убедится что сообщения реально ходят? Можно активировать SysRQ механизм ядра.
echo 1 > /proc/sys/kernel/sysrq
echo h > /proc/sysrq-trigger
После этого на сервере который принимает сообщения в окне с netcat появится текст типа
[ 7849.700372] SysRq : HELP : loglevel(0-9).
Источник
Лёг сервер
 Пятница, мой сервер рухнул. Я знал, за несколько дней, что один из жестких дисков умирал на нём. Умирающий сервак каждый раз мне напоминал по электронной почте, что у него существуют проблемы с первым жёстким диском, как раз на котором установлена операционная система Линукс и вся веб-халабуда. Наконец, я дождался выходных и пошёл покупать в замену старому винту — новый. У меня есть нехорошие примеры, где точно так же у ребят лёг сервер!
Пятница, мой сервер рухнул. Я знал, за несколько дней, что один из жестких дисков умирал на нём. Умирающий сервак каждый раз мне напоминал по электронной почте, что у него существуют проблемы с первым жёстким диском, как раз на котором установлена операционная система Линукс и вся веб-халабуда. Наконец, я дождался выходных и пошёл покупать в замену старому винту — новый. У меня есть нехорошие примеры, где точно так же у ребят лёг сервер!
Утром в пятницу, сервер ещё делал «смешные» шумы — то пердел, то эпелептически жжужжал. Я понимал, что ремонт сервера не будет ждать выходных дней, да и в падлу админу в выходные отрываться от семьи и отдыха. В любом случае, этот гиморой должен быть решён мининум за час, а то вся наша фирма просто «ляжет» от работы Почты, до VPN-доступа.
Какие попытки я предпринял, что бы поиметь «минимум гемороя» с серваком:
1. Сделал полностью резервное копирование. 1%, 10%, 99% сделано, готово!
2. Заменил жёсткий диск
3. Начал с загрузки с CD-ROMа системы
4. Вставил флешку или диск с резервным бакапом данных
Мои попытки восстановиться с бэкапа оказались напрасны!
Фиг два! Когда я вставляю флешку с бакапом данных, я получаю ответ: «Резервная копия не найдена«. Я беру резервную копию со своего сервака и пытаюсь пихнуть её на новоустановленную другую систему или винт. И так, давайте ещё раз попробуем сделать другую резервную копию жёсткого диска, что бы затем поставить её на новый. Но сначала, мы отбэкапим старый винт, и попробуем его же восстановить — его же собственной резервной копией.
Хрен там! Сервер не признаёт даже его собственной копии жесткого диска. Проверьте, все пути сохранения копий должны быть идентично одинаковые. Попробуем восстановить данные из бакапа ещё раз на старом серваке… И что теперь?
Быстрые пути решения данной проблеммы с восстановлением сервака:
1. У меня есть другой компьютер, который станет моим новым сервером.
2. Я установил туда новый софт для сервера с нуля.
3. У меня есть другая резервная копия с Backupом за последние 92 дня записи данных и Конфигураций. Но это не правильно, там же нет пользовательского интерфейса, и все команды можно запускать только в командной строке в чёрном экране. Нам нужно просто понять, как правильно сделать восстановление сервера с поддержкой графической оболочки. После различных поисков в Инете я понял — как правильно восстановить свой новый сервак из старого.
4. Я включил опцию «автоматическое восстановление данных» и подсунул бакап от «старого сервака» там есть такая функция данных.
5. Ещё раз проверил все конфигурации и настройки — всё должно быть нормально. Но если бы я прописывал «все конфиги с нуля» всё это с нуля то у меня это заняло бы минимум 2-3 дня торчания у сервака.
В итоге, новым серваком стал обычный компьютер, на который я в выходных поставил жёсткий диск и отдал место на нём под резервные копии восстановления данных. Новый сервак был предустановлен лишь предустановленной оболочкой Линухи и грамонтым бакапом конфига системы и данных.
Через 2 часа почтовый сервер был снова в деле. Ещё через 3 часа после этого, обновились старые зоны Name Server и заработали web-сайты всех моих клиентов.
Когда у вас лёг сервер:
1. Если у вас есть резервная копия, это не означает, что вы можете восстановить данные. Вы проверили это?
2. Использование провайдера для размещения веб-сайт не лучшее. Я знаю нескольких админов, и когда их сайт вышел из строя мы так и не смогли восстановить данные удалённо. Внимательно читайте, что написано внизу мелким шрифтом в договоре с провайдером: они делают регулярные резервные копии, но они не могут нести ответственность за них или их повреждение.
3. Всегда проверяйте и тестируйте сервер, а лучше используйте специальный программы-утилиты. Лучший вариант — это когда вы делаете: 2 различных резервных копий с помощью различных методов.
Если у вас лёг сервер не расстраивайтесь, вы всегда, в течении часа сможете восстановить все данные. Хуже если вы будете настраивать и конфигурить новый сервер с нуля. Удачи!
Источник
Пять шагов к спасению Linux-сервера, который рухнул
Мне доводилось видеть множество Linux-серверов, которые, без единой перезагрузки, работали годами, в режиме 24×7. Но ни один компьютер не застрахован от неожиданностей, к которым могут вести «железные», программные и сетевые сбои. Даже самый надёжный сервер может однажды отказать. Что делать? Сегодня вы узнаете о том, что стоит предпринять в первую очередь для того, чтобы выяснить причину проблемы и вернуть машину в строй.

Поиск и устранение неполадок: раньше и теперь
Когда, в 1980-х, я начал работать системным администратором Unix — задолго до того, как Линус Торвальдс загорелся идеей Linux — если с сервером было что-то не так, это была реальная засада. Тогда было сравнительно мало инструментов для поиска проблем, поэтому для того, чтобы сбойный сервер снова заработал, могло понадобиться много времени.
Теперь всё совсем не так, как раньше. Как-то один системный администратор вполне серьёзно сказал мне, говоря о проблемном сервере: «Я его уничтожил и поднял новый».
В былые времена такое звучало бы дико, но сегодня, когда ИТ-инфраструктуры строят на основе виртуальных машин и контейнеров… В конце концов, развёртывание новых серверов по мере необходимости — это обычное дело в любой облачной среде.
Сюда надо добавить инструменты DevOps, такие, как Chef и Puppet, используя которые легче создать новый сервер, чем диагностировать и «чинить» старый. А если говорить о таких высокоуровневых средствах, как Docker Swarm, Mesosphere и Kubernetes, то благодаря им работоспособность отказавшего сервера будет автоматически восстановлена до того, как администратор узнает о проблеме.
Данная концепция стала настолько распространённой, что ей дали название — бессерверные вычисления. Среди платформ, которые предоставляют подобные возможности — AWS Lambda, Iron.io, Google Cloud Functions.
Благодаря такому подходу облачный сервис отвечает за администрирование серверов, решает вопросы масштабирования и массу других задач для того, чтобы предоставить клиенту вычислительные мощности, необходимые для запуска его приложений.
Бессерверные вычисления, виртуальные машины, контейнеры — все эти уровни абстракции скрывают реальные серверы от пользователей, и, в некоторой степени, от системных администраторов. Однако, в основе всего этого — физическое аппаратное обеспечение и операционные системы. И, если что-то на данном уровне вдруг разладится, кто-то должен привести всё в порядок. Именно поэтому то, о чём мы сегодня говорим, никогда не потеряет актуальности.
Помню разговор с одним системным оператором. Вот что он говорил о том, как надо поступать после сбоя: «Переустановка сервера — это путь вникуда. Так не понять — что стало с машиной, и как не допустить такого в будущем. Ни один сносный администратор так не поступает». Я с этим согласен. До тех пор, пока не обнаружен первоисточник проблемы, её нельзя считать решённой.
Итак, перед нами сервер, который дал сбой, или мы, по крайней мере, подозреваем, что источник неприятностей именно в нём. Предлагаю вместе пройти пять шагов, с которых стоит начинать поиск и решение проблем.
Шаг первый. Проверка аппаратного обеспечения
В первую очередь — проверьте железо. Я знаю, что звучит это тривиально и несовременно, но, всё равно — сделайте это. Встаньте с кресла, подойдите к серверной стойке и удостоверьтесь в том, что сервер правильно подключён ко всему, необходимому для его нормальной работы.
Я и сосчитать не смогу, сколько раз поиски причины проблемы приводили к кабельным соединениям. Один взгляд на светодиоды — и становится ясно, что Ethernet-кабель выдернут, или питание сервера отключено.
Конечно, если всё выглядит более-менее прилично, можно обойтись без визита к серверу и проверить состояние Ethernet-соединения такой командой:
Если её ответ можно трактовать, как «да», это значит, что исследуемый интерфейс способен обмениваться данными по сети.
Однако, не пренебрегайте возможностью лично осмотреть устройство. Это поможет, например, узнать, что кто-то выдернул какой-нибудь важный кабель и обесточил таким образом сервер или всю стойку. Да, это до смешного просто, но удивительно — как часто причина отказа системы именно в этом.
Ещё одну распространённую аппаратную проблему невооружённым взглядом не распознать. Так, сбойная память является причиной всевозможных проблем.
Виртуальные машины и контейнеры могут скрывать эти проблемы, но если вы столкнулись с закономерным появлением отказов, связанных с конкретным физическим выделенным сервером, проверьте его память.
Для того, чтобы увидеть, что BIOS/UEFI сообщают об аппаратном обеспечении компьютера, включая память, используйте команду dmidecode:
Даже если всё тут выглядит нормально, на самом деле это может быть и не так. Дело в том, что данные SMBIOS не всегда точны. Поэтому, если после dmidecode память всё ещё остаётся под подозрением — пришло время воспользоваться Memtest86. Это отличная программа для проверки памяти, но работает она медленно. Если вы запустите её на сервере, не рассчитывайте на возможность использовать эту машину для чего-нибудь другого до завершения проверки.
Если вы сталкиваетесь со множеством проблем с памятью — я видел такое в местах, отличающихся нестабильным электропитанием — нужно загрузить модуль ядра Linux edac_core. Этот модуль постоянно проверяет память в поиске сбойных участков. Для того, чтобы загрузить этот модуль, воспользуйтесь такой командой:
Подождите какое-то время и посмотрите, удастся ли что-нибудь увидеть, выполнив такую команду:
Эта команда даст вам сводку о числе ошибок, разбитых по модулям памяти (показатели, название которых начинается с csrow ). Эти сведения, если сопоставить их с с данными dmidecode о каналах памяти, слотах и заводских номерах компонентов, помогут выявить сбойную планку памяти.
Шаг второй. Поиск истинного источника проблемы
Итак, сервер стал странно себя вести, но дым из него ещё пока не идёт. В сервере ли дело? Прежде чем вы попытаетесь решить возникшую проблему, сначала нужно точно определить её источник. Скажем, если пользователи жалуются на странности с серверным приложением, сначала проверьте, что причина проблемы — не в сбоях на клиенте.
Например, друг однажды рассказал мне, как его пользователи сообщили о том, что не могут работать с IBM Tivoli Storage Manager. Сначала, конечно, казалось, что виновен во всём сервер. Но в итоге администратор выяснил, что проблема вообще не была связана с серверной частью. Причиной был неудачный патч Windows-клиента 3076895. Но то, как сбоило это обновление безопасности, делало происходящее похожим на проблему серверной стороны.
Кроме того, нужно понять, является ли причиной проблемы сам сервер, или серверное приложение. Например, серверная программа может работать кое как, а железо оказывается в полном порядке.
Для начала — самое очевидное. Работает ли приложение? Есть множество способов проверить это. Вот два моих любимых:
Если оказалось, что, например, веб-сервер Apache не работает, запустить его можно такой командой:
Если в двух словах, то прежде чем диагностировать сервер и искать причину проблему, узнайте — сервер ли виноват, или что-то другое. Только тогда, когда вы поймёте, где именно находится источник сбоя, вы сможете задавать правильные вопросы и переходить к дальнейшему анализу того, что произошло.
Это можно сравнить с неожиданной остановкой автомобиля. Вы знаете, что машина дальше не едет, но, прежде чем тащить её в сервис, хорошо бы проверить, есть ли бензин в баке.
Шаг третий. Использование команды top
Итак, если оказалось, что все пути ведут к серверу, то вот ещё один важный инструмент для проверки системы — команда top . Она позволяет узнать среднюю нагрузку на сервер, использование файла подкачки, выяснить, какие ресурсы системы используют процессы. Эта утилита показывает общие сведения о системе и выводит данные по всем выполняющимся процессам на Linux-сервере. Вот подробное описание данных, которые выводит эта команда. Тут можно найти массу информации, которая способна помочь в поиске проблем с сервером. Вот несколько полезных способов работы с top , позволяющих найти проблемные места.
Для того, чтобы обнаружить процесс, потребляющий больше всего памяти, список процессов надо отсортировать в интерактивном режиме, введя с клавиатуры M . Для того, чтобы выяснить приложение, потребляющее больше всего ресурсов процессора, отсортируйте список, введя P . Для сортировки процессов по времени активности, введите с клавиатуры T . Для того, чтобы лучше видеть колонку, по которой производится сортировка, нажмите клавишу b .
Кроме того, данные по процессам, выводимые командой в интерактивном режиме, можно отфильтровать, введя O или o . Появится следующее приглашение, где предлагается добавить фильтр:
Затем можно ввести шаблон, скажем, для фильтрации по конкретному процессу. Например, благодаря фильтру COMMAND=apache , программа будет выводить только сведения о процессах Apache.
Ещё одна полезная возможность top заключается в выводе полного пути процесса и аргументов запуска. Для того, чтобы просмотреть эти данные, воспользуйтесь клавишей c .
Ещё одна похожая возможность top активируется вводом символа V . Она позволяет переключиться в режим иерархического вывода сведений о процессах.
Кроме того, можно просматривать процессы конкретного пользователя с помощью клавиш u или U , или скрыть процессы, не потребляющих ресурсы процессора, нажав клавишу i .
Хотя top долго была самой популярной интерактивной утилитой Linux для просмотра текущей ситуации в системе, у неё есть и альтернативы. Например, существует программа htop обладает расширенным набором возможностей, которая отличается более простым и удобным графическим интерфейсом Ncurses. Работая с htop , можно пользоваться мышью и прокручивать список процессов по вертикали и по горизонтали для того, чтобы просмотреть их полный список и полные командные строки.
Я не жду, что top сообщит мне — в чём проблема. Скорее, я использую этот инструмент для того, чтобы найти нечто, что заставит подумать: «А это уже интересно», и вдохновит меня на дальнейшие исследования. Основываясь на данных от top , я знаю, например, на какие логи стоит взглянуть в первую очередь. Логи я просматриваю, используя комбинации команд less , grep и tail -f .
Шаг четвёртый. Проверка дискового пространства
Даже сегодня, когда в кармане можно носить терабайты информации, на сервере, совершенно незаметно, может кончиться дисковое пространство. Когда такое происходит — можно увидеть весьма странные вещи.
Разобраться с дисковым пространством нам поможет старая добрая команда df, имя которой является сокращением от «disk filesystem». С её помощью можно получить сводку по свободному и использованному месту на диске.
Обычно df используют двумя способами.
показывает данные о жёстких дисках в удобном для восприятия виде. Например, сведения об объёме накопителя выводятся в гигабайтах, а не в виде точного количества байт.
Ещё один полезный флаг df — T . Он позволяет вывести данные о типах файловых систем хранилищ. Например, команда вида $ sudo df -hT показывает и объём занятого пространства диска, и данные о его файловой системе.
Если что-то кажется вам странным, можно копнуть глубже, воспользовавшись командой Iostat. Она является частью sysstat — продвинутого набора инструментов для мониторинга системы. Она выводит сведения о процессоре, а также данные о подсистеме ввода-вывода для блочных устройств хранения данных, для разделов и сетевых файловых систем.
Вероятно, самый полезный способ вызова этой команды выглядит так:
Такая команда выводит сведения об объёме прочитанных и записанных данных для устройства. Кроме того, она покажет среднее время операций ввода-вывода в миллисекундах. Чем больше это значение — тем вероятнее то, что накопитель перегружен запросами, или перед нами — аппаратная проблема. Что именно? Тут можно воспользоваться утилитой top для того, чтобы выяснить, нагружает ли сервер MySQL (или какая-нибудь ещё работающая на нём СУБД). Если подобных приложений найти не удалось, значит есть вероятность, что с диском что-то не так.
Ещё один важный показатель можно найти в разделе %util , где выводятся сведения об использовании устройства. Этот показатель указывает на то, как напряжённо работает устройство. Значения, превышающие 60% указывают на низкую производительность дисковой подсистемы. Если значение близко к 100%, это означает, что диск работает на пределе возможностей.
Работая с утилитами для проверки дисков, обращайте внимание, что именно вы анализируете.
Например, нагрузка в 100% на логический диск, который представляет собой несколько физических дисков, может означать лишь то, что система постоянно обрабатывает какие-то операции ввода-вывода. Значение имеет то, что именно происходит на физических дисках. Поэтому, если вы анализируете логический диск, помните, что дисковые утилиты не дадут полезной информации.
Шаг пятый. Проверка логов
Последнее в нашем списке, но лишь по порядку, а не по важности — проверка логов. Обычно их можно найти по адресу /var/log , в отдельных папках для различных сервисов.
Для новичков в Linux лог-файлы могут выглядеть как ужасная мешанина. Это — текстовые файлы, в которые записываются сведения о том, чем занимаются операционная система и приложения. Есть два вида записей. Одни записи — это то, что происходит в системе или в программе, например — каждая транзакция или перемещение данных. Вторые — сообщения об ошибках. В лог-файлах может содержаться и то, и другое. Эти файлы могут быть просто огромными.
Данные в файлах журналов обычно выглядят довольно таинственно, но вам всё равно придётся с ними разобраться. Вот, например, хорошее введение в эту тему от Digital Ocean.
Есть множество инструментов, которые помогут вам проверить логи. Например — dmesg. Эта утилита выводит сообщения ядра. Обычно их очень и очень много, поэтому используйте следующий простой сценарий командной строки для того, чтобы просмотреть 10 последних записей:
Хотите следить за происходящим в реальном времени? Мне, определённо, это нужно, когда я занимаюсь поиском проблем. Для того, чтобы этого добиться, используйте команду tail с ключом -f . Выглядит это так:
Вышеприведённая команда наблюдает за файлом syslog , и когда в него попадают сведения о новых событиях, выводит их на экран.
Вот ещё один удобный сценарий командной строки:
Он сканирует логи и показывает возможные проблемы.
Если в вашей системе применяется systemd то, вам нужно будет использовать встроенное средство для работы с журналами — Journalctl. Systemd централизует управление логированием с помощью демона journald . В отличие от других логов Linux, journald хранит данные в двоичном, а не в текстовом формате.
Бывает полезно настроить journald так, чтобы он сохранял логи после перезагрузки системы. Сделать это можно, воспользовавшись такой командой:
Для включения постоянного хранения записей понадобится отредактировать файл /etc/systemd/journald.conf , включив в него следующее:
Самый распространённый способ работать с этими журналами — такая команда:
Она покажет все записи журналов после последней перезагрузки. Если система была перезагружена, посмотреть, что было до этого, можно с помощью такой команды:
Это позволит просмотреть записи журналов, сделанные в предыдущую сессию сервера.
Вот полезный материал о том, как пользоваться journalctl .
Логи бывают очень большими, с ними сложно работать. Поэтому, хотя разобраться с ними можно с помощью средств командной строки, таких, как grep , awk , и других, полезно бывает задействовать специальные программы для просмотра логов.
Мне, например, нравится система для управления логами с открытым кодом Graylog. Она собирает, индексирует и анализирует самые разные сведения. В её основе лежат MongoDB для работы с данными и Elasticsearch для поиска по лог-файлам. Graylog упрощает отслеживание состояния сервера. Graylog, если сравнить её со встроенными средствами Linux, проще и удобнее. Кроме того, среди её полезных возможностей можно отметить возможность работы с многими DevOps-системами, такими, как Chef, Puppet и Ansible.
Итоги
Как бы вы ни относились к вашему серверу, возможно, он не попадёт в Книгу Рекордов Гиннеса как тот, который проработал дольше всех. Но стремление сделать сервер как можно более стабильным, добираясь до сути неполадок и исправляя их — достойная цель. Надеемся, то, о чём мы сегодня рассказали, поможет вам достичь этой цели.
Уважаемые читатели! А как вы обычно поступаете с упавшими серверами?
Источник


