- 4. Уровень значимости
- Уровень значимости в статистике
- Определение
- История вопроса
- Введение фиксированного коэффициента
- Значение p-уровня
- Проверка статистических гипотез
- Эффективность
- Уровни статистической значимости
- Уровень статистической значимости (р)
- Откуда берется уровень статистической значимости «р»
- Что показывает уровень статистической значимости «р»
- Какой уровень статистической значимости лучше: 0,01 или 0,05
4. Уровень значимости
Уровни статистической значимости
Уровень значимости – это вероятность того, что мы сочли различия существенными, в то время как они на самом деле случайны.
Итак, уровень значимости имеет дело с вероятностью.
Уровень значимости показывает степень достоверности выявленных различий между выборками, т.е. показывает, насколько мы можем доверять тому, что различия действительно есть.
Современные научные исследования требуют обязательных расчётов уровня статистической значимости результатов.
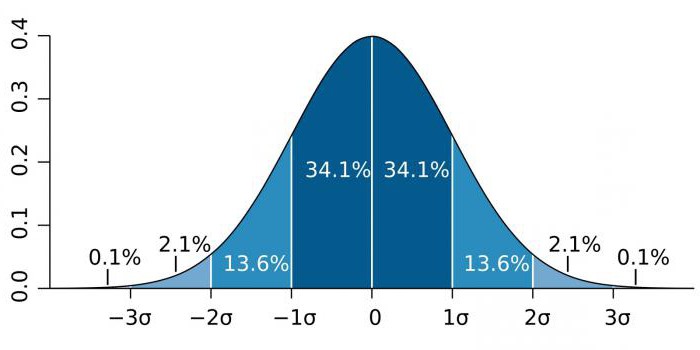
Обычно в прикладной статистике используют 3 уровня значимости.
Это 5%-ный уровень значимости. До 5% составляет вероятность того, что мы ошибочно сделали вывод о том, что различия достоверны, в то время как они недостоверны на самом деле. Можно сказать и по-другому: мы лишь на 95% уверены в том, что различия действительно достоверны. В данном случае можно написать и так: P> 0,95. Общий смысл критерия останется тем же.
Это 1%-ный уровень значимости. Вероятность ошибочного вывода о том, что различия достоверны, составляет не более 1%. Можно сказать и по-другому: мы на 99% уверены в том, что различия действительно достоверны. В данном случае можно написать и так: P> 0,99. Смысл останется тем же.
Это 0,1%-ный уровень значимости. Всего 0,1% составляет вероятность того, что мы сделали ошибочный вывод о том, что различия достоверны. Это — самый надёжный вариант вывода о достоверности различий. Можно сказать и по-другому: мы на 99,9% уверены в том, что различия действительно достоверны. В данном случае можно написать и так: P> 0,999. Смысл опять-таки останется тем же.
Уровень значимости – это вероятность ошибочного отклонения (отвержения) гипотезы, в то время как она на самом деле верна. Речь идёт об отклонении нулевой гипотезы Н о .
Уровень значимости – это допустимая ошибка в нашем утверждении, в нашем выводе.
Возможны ошибки двух родов: первого рода ( α ) и второго рода ( β ).
Ошибка I рода – мы отклонили нулевую гипотезу, в то время как она верна.
α – ошибка I рода.
Вероятность того, что принято правильное решение: 1 – α = 0,95, или 95%.
Уровни значимости для ошибок I рода
1. α ≤ 0,05 – низший уровень
Низший уровень значимости – позволяет отклонять нулевую гипотезу, но еще не разрешает принять альтернативную.
2. α ≤ 0,01 – достаточный уровень
Достаточный уровень – позволяет отклонять нулевую гипотезу и принимать альтернативную.
G – критерий знаков
T – критерий Вилкоксона
U – критерий Манна – Уитни.
Для них обратное соотношение.
3. α ≤ 0,001 – высший уровень значимости.
На практике различия считают достоверными при р ≤ 0,05.
Для ненаправленной статистической гипотезы используется двусторонний критерий значимости. Он более строгий, так как проверяет различия в обе стороны: в сторону нулевой гипотезы и в сторону альтернативной. Поэтому для него используется критерий значимости 0,01.
Мощность критерия – его способность выявлять даже мелкие различия если они есть. Чем мощнее критерий, тем лучше он отвергает нулевую гипотезу и подтверждает альтернативную.
Здесь появляется понятие: ошибка II рода.
Ошибка II рода – это принятие нулевой гипотезы, хотя она не верна.
Мощность критерия: 1 – β
Чем мощнее критерий, тем он привлекательнее для исследователя. Он лучше отвергает нулевую гипотезу.
Чем привлекательны маломощные критерии?
Достоинства маломощных критериев
Широкий диапазон, по отношению к самым разным данным
Применимость к неравным по объему выборкам.
Большая информативность результатов.
Самый популярный статистический критерий в России — Т-критерий Стьюдента. Но всего в 30% статей его используют правильно, а в 70% — неправильно, т.к. не проверяют предварительно выборку на нормальность распределения.
Второй по популярности — критерий хи-квадрат, χ 2
Т-критерий Стьюдента – это частный случай дисперсионного анализа для более маленькой по объёму выборки.
Источник
Уровень значимости в статистике
Уровень значимости в статистике является важным показателем, отражающим степень уверенности в точности, истинности полученных (прогнозируемых) данных. Понятие широко применяется в различных сферах: от проведения социологических исследований, до статистического тестирования научных гипотез.

Определение
Уровень статистической значимости (или статистически значимый результат) показывает, какова вероятность случайного возникновения исследуемых показателей. Общая статистическая значимость явления выражается коэффициентом р-value (p-уровень). В любом эксперименте или наблюдении существует вероятность, что полученные данные возникли из-за ошибок выборки. Особенно это актуально для социологии.
То есть статистически значимой является величина, чья вероятность случайного возникновения крайне мала либо стремится к крайности. Крайностью в этом контексте считают степень отклонения статистики от нуль-гипотезы (гипотезы, которую проверяют на согласованность с полученными выборочными данными). В научной практике уровень значимости выбирается перед сбором данных и, как правило, его коэффициент составляет 0,05 (5 %). Для систем, где крайне важны точные значения, этот показатель может составлять 0,01 (1 %) и менее.
История вопроса
Понятие уровня значимости было введено британским статистиком и генетиком Рональдом Фишером в 1925 году, когда он разрабатывал методику проверки статистических гипотез. При анализе какого-либо процесса существует определенная вероятность тех либо иных явлений. Трудности возникают при работе с небольшими (либо не очевидными) процентами вероятностей, подпадающими под понятие «погрешность измерений».
При работе со статистическими данными, недостаточно конкретными, чтобы их проверить, ученые сталкивались с проблемой нулевой гипотезы, которая «мешает» оперировать малыми величинами. Фишер предложил для таких систем определить вероятность событий в 5 % (0,05) в качестве удобного выборочного среза, позволяющего отклонить нуль-гипотезу при расчетах.
Введение фиксированного коэффициента
В 1933 году ученые Ежи Нейман и Эгон Пирсон в своих работах рекомендовали заранее (до сбора данных) устанавливать определенный уровень значимости. Примеры использования этих правил хорошо видны во время проведения выборов. Предположим, есть два кандидата, один из которых очень популярен, а второй – малоизвестен. Очевидно, что первый кандидат выборы выиграет, а шансы второго стремятся к нулю. Стремятся – но не равны: всегда есть вероятность форс-мажорных обстоятельств, сенсационной информации, неожиданных решений, которые могут изменить прогнозируемые результаты выборов.
Нейман и Пирсон согласились, что предложенный Фишером уровень значимости 0,05 (обозначаемый символом α) наиболее удобен. Однако сам Фишер в 1956 году выступил против фиксации этого значения. Он считал, что уровень α должен устанавливаться в соответствии с конкретными обстоятельствами. Например, в физике частиц он составляет 0,01.
Значение p-уровня
Термин р-value впервые использован в работах Браунли в 1960 году. P-уровень (p-значение) является показателем, находящимся в обратной зависимости от истинности результатов. Наивысший коэффициент р-value соответствует наименьшему уровню доверия к произведенной выборке зависимости между переменными.
Данное значение отражает вероятность ошибок, связанных с интерпретацией результатов. Предположим, p-уровень = 0,05 (1/20). Он показывает пятипроцентную вероятность того, что найденная в выборке связь между переменными – всего лишь случайная особенность проведенной выборки. То есть, если эта зависимость отсутствует, то при многократных подобных экспериментах в среднем в каждом двадцатом исследовании можно ожидать такую же либо большую зависимость между переменными. Часто p-уровень рассматривается в качестве «допустимой границы» уровня ошибок.
Кстати, р-value может не отражать реальную зависимость между переменными, а лишь показывает некое среднее значение в пределах допущений. В частности, окончательный анализ данных будет также зависеть от выбранных значений данного коэффициента. При p-уровне = 0,05 будут одни результаты, а при коэффициенте, равном 0,01, другие.
Проверка статистических гипотез
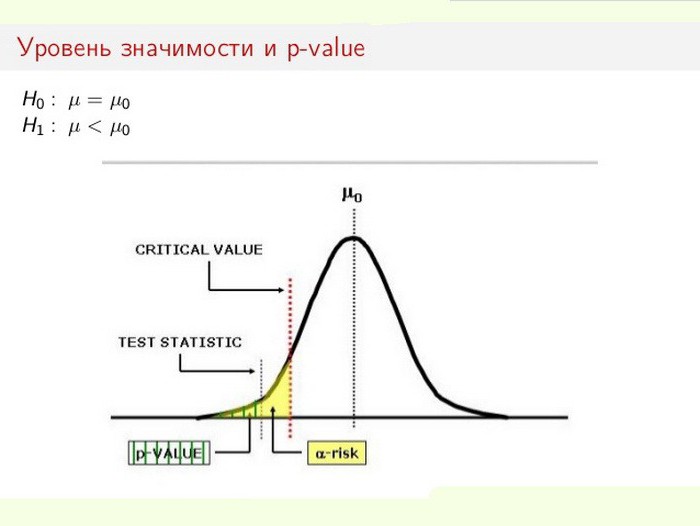
Уровень статистической значимости особенно важен при проверке выдвигаемых гипотез. Например, при расчетах двустороннего теста область отторжения разделяют поровну на обоих концах выборочного распределения (относительно нулевой координаты) и высчитывают истинность полученных данных.
Предположим, при мониторинге некоего процесса (явления) выяснилось, что новая статистическая информация свидетельствует о небольших изменениях относительно предыдущих значений. При этом расхождения в результатах малы, не очевидны, но важны для исследования. Перед специалистом встает дилемма: изменения реально происходят или это ошибки выборки (неточность измерений)?
В этом случае применяют либо отвергают нулевую гипотезу (списывают все на погрешность, или признают изменение системы как свершившийся факт). Процесс решения задачи базируется на соотношении общей статистической значимости (р-value) и уровня значимости (α). Если р-уровень -8 , что не являются редкостью для этой области.
Эффективность
Необходимо учитывать, что коэффициенты α и р-value не являются точными характеристиками. Каким бы ни был уровень значимости в статистике исследуемого явления, он не является безусловным основанием для принятия гипотезы. Например, чем меньше значение α, тем больше шанс, что устанавливаемая гипотеза значима. Однако существует риск ошибиться, что уменьшает статистическую мощность (значимость) исследования.
Исследователи, которые зацикливаются исключительно на статистически значимых результатах, могут получить ошибочные выводы. При этом перепроверить их работу затруднительно, так как ими применяются допущения (коими фактически и являются значения α и р-value). Поэтому рекомендуется всегда, наряду с вычислением статистической значимости, определять другой показатель – величину статистического эффекта. Величина эффекта – это количественная мера силы эффекта.
Источник
Уровни статистической значимости
Результаты математической обработки данных почти любым методом в конечном итоге оцениваются по уровню статистической значимости полученного результата. Это может быть уровень значимости коэффициента корреляции (Пирсона, Спирмена), уровень значимости различий по результатам сравнения выборок по тому или иному статистическому критерию (Стьюдента, Манна-Уитни, Вилкоксона, Хи-квадрат) и т.п. — вне зависимости от используемого метода, уровни значимости оцениваются одинаково.
Уровень статистической значимости обозначается латинской буквой p. Традиционно выделяют три уровня статистической значимости результатов математической обработки данных:
- P≤0,05 — обычный уровень статистической значимости. Его можно интерпретировать так: «получен статистически значимый результат». Для наглядности традиционно обозначается одной звездочкой.
- P≤0,01 — высокий уровень значимости. Его можно интерпретировать следующим образом: «обнаружена выраженная закономерность», например, тесная связь между двумя переменными, если речь идет об уровне значимости коэффициента корреляции. Традиционно обозначается двумя звездочками.
- P≤0,001 — очень высокий уровень значимости. Обозначается тремя звездочками.
Кроме того, иногда в результатах исследований выделяют и описывают также близкие к статистически значимым результаты (p≈0,05). Сюда можно отнести такие показатели статистической значимости, как 0,06, 0,07, 0,08 и 0,09. Они свидетельствуют о наличии тенденции к существованию соответствующей закономерности.
Что касается показателей статистической значимости величиной от 0,1 и выше — они говорят о том, что полученный результат не является статистически значимым. Например, если речь идет о сравнении выборок, то подобный показатель свидетельствует об отсутствии статистически значимых различий между сравниваемыми выборками.
По сути уровень статистической значимости отражает вероятность ошибки в выявлении закономерности. Поэтому чем меньше величина показателя p, тем ниже вероятность ошибки, тем более статистически значимым является полученный результат.
Источник
Уровень статистической значимости (р)
В таблицах результатов статистических расчётов в курсовых, дипломных и магистерских работах по психологии всегда присутствует показатель «р».
Например, в соответствии с задачами исследования были рассчитаны различия уровня осмысленности жизни у мальчиков и девочек подросткового возраста.
Уровень статистической значимости (p)
Мальчики (20 чел.)
Локус контроля — «Я»
Локус контроля — «Жизнь»
* — различия статистически достоверны (р≤0,05)
В правом столбце указано значение «р» и именно по его величине можно определить значимы различия осмысленности жизни в будущем у мальчиков и девочек или не значимы. Правило простое:
- Если уровень статистической значимости «р» меньше либо равен 0,05, то делаем вывод, что различия значимы. В приведенной таблице различия между мальчиками и девочками значимы в отношении показателя «Цели» — осмысленность жизни в будущем. У девочек этот показатель статистически значимо выше, чем у мальчиков.
- Если уровень статистической значимости «р» больше 0,05, то делается заключение, что различия не значимы. В приведенной таблице различия между мальчиками и девочками не значимы по всем остальным показателям, за исключением первого.
Откуда берется уровень статистической значимости «р»
Уровень статистической значимости вычисляется статистической программой вместе с расчётом статистического критерия. В этих программах можно также задать критическую границу уровня статистической значимости и соответствующие показатели будут выделяться программой.
Например, в программе STATISTICA при расчете корреляций можно установить границу «р», например, 0,05 и все статистически значимые взаимосвязи будут выделены красным цветом.
Если расчёт статистического критерия проводится вручную, то уровень значимости «р» выявляется путем сравнения значения полученного критерия с критическим значением.
Что показывает уровень статистической значимости «р»
Все статистические расчеты носят приблизительный характер. Уровень этой приблизительности и определяет «р». Уровень значимости записывается в виде десятичных дробей, например, 0,023 или 0,965. Если умножить такое число на 100, то получим показатель р в процентах: 2,3% и 96,5%. Эти проценты отражают вероятность ошибочности нашего предположения о взаимосвязи, например, между агрессивностью и тревожностью.
То есть, коэффициент корреляции 0,58 между агрессивностью и тревожностью получен при уровне статистической значимости 0,05 или вероятности ошибки 5%. Что это конкретно означает?
Выявленная нами корреляция означает, что в нашей выборке наблюдается такая закономерность: чем выше агрессивность, тем выше тревожность. То есть, если мы возьмем двух подростков, и у одного тревожность будет выше, чем у другого, то, зная о положительной корреляции, мы можем утверждать, что у этого подростка и агрессивность будет выше. Но так как в статистике все приблизительно, то, утверждая это, мы допускаем, что можем ошибиться, причем вероятность ошибки 5%. То есть, сделав 20 таких сравнений в этой группе подростков, мы можем 1 раз ошибиться с прогнозом об уровне агрессивности, зная тревожность.
Какой уровень статистической значимости лучше: 0,01 или 0,05
Уровень статистической значимости отражает вероятность ошибки. Следовательно, результат при р=0,01 более точный, чем при р=0,05.
В психологических исследованиях приняты два допустимых уровня статистической значимости результатов:
р=0,01 – высокая достоверность результата сравнительного анализа или анализа взаимосвязей;
р=0,05 – достаточная точность.
Надеюсь, эта статья поможет вам написать работу по психологии самостоятельно. Если понадобится помощь, обращайтесь (все виды работ по психологии; статистические расчеты). Заказать
Источник


