- Разреженные файлы в NTFS
- Разреженный файл — Sparse file
- СОДЕРЖАНИЕ
- Преимущества
- Недостатки
- Разреженные файлы в Unix
- Творчество
- Обнаружение
- Копирование
- Работа с разреженными наборами данных в пандах и склеарне
- Что такое разреженная матрица?
- Набор данных
- Горячее кодирование
- Панды Разреженные Структуры
- Сплит X, у
- Поезд-тест сплит и обучение модели
- Scipy разреженные матрицы
Разреженные файлы в NTFS
В NTFS есть поддержка разреженных файлов (sparse files). Это такие файлы, которые занимают меньше дискового пространства, чем их собственный размер. Данная технология не имеет отношения к встроенной в NTFS поддержке компрессии файлов, так как экономия места на диске в sparse-файлах основана на другом принципе. Никакого сжатия данных не осуществляется. Вместо этого, в файле высвобождаются области, занятые одними лишь нулями (0x00). Приложение, читающее разреженный файл, дойдя до области с нулями, прочитает нули, но реального чтения с диска не произойдёт.
Таким образом можно создавать файлы гигантского размера, состоящие из нулей, но на диске они могут занимать всего лишь несколько килобайт. Реальное дисковое пространство выделяется тогда, когда вместо 0x00 записываются какие-то другие данные. Разреженность поможет сэкономить дисковое пространство только в таких файлах, в которых есть действительно большие пустые области.
Демонстрировать работу с разреженными файлами я буду с помощью системной утилиты fsutil в командной строке.
Создадим с помощью утилиты пустой файл большого размера:
fsutil file createnew test.nul 10000000000
Присвоим файлу атрибут «sparse»:
fsutil sparse setflag test.nul
Сам по себе атрибут ещё не приводит к экономии дискового пространства. Нужно ещё разметить внутри файла область, которая будет освобождена. У нас весь файл пустой, так что область можно задать в размер файла.
fsutil sparse setrange test.nul 0 10000000000
Готово. Смотрим результат. 
Как проделывать эти операции в своих программах с помощью API функций, можете посмотреть в исходном коде небольшой утилиты, которую я написал в 2006-м. Она тоже консольная, и тоже как fsutil умеет присваивать атрибут sparse и задавать диапазон освобождаемой области. Кроме того, моя программка может сама искать в файле пустые области больше некоторого заданного размера и освобождать их. Отпадает необходимость самому вычислять смещения.
Источник
Разреженный файл — Sparse file
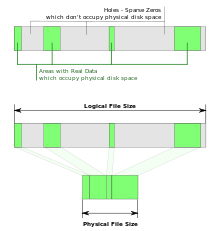
В информатике , разреженный файл представляет собой тип компьютерного файла , который пытается использовать файловую систему более эффективно , когда пространство сам файл частично опорожнить. Это достигается путем записи на диск краткой информации ( метаданных ), представляющей пустые блоки, вместо фактического «пустого» пространства, составляющего блок, с использованием меньшего дискового пространства. Полный размер блока записывается на диск как фактический размер только в том случае, если блок содержит «реальные» (непустые) данные.
При чтении разреженных файлов файловая система прозрачно преобразует метаданные, представляющие пустые блоки, в «настоящие» блоки, заполненные нулевыми байтами во время выполнения. Приложение не знает об этом преобразовании.
Большинство современных файловых систем поддерживают разреженные файлы, включая большинство вариантов Unix и NTFS . Apple HFS + не поддерживает разреженные файлы, но в OS X уровень виртуальной файловой системы поддерживает их хранение в любой поддерживаемой файловой системе, включая HFS +. Файловая система Apple (APFS), анонсированная в июне 2016 года на WWDC, также поддерживает их. Разреженные файлы обычно используются для образов дисков , моментальных снимков баз данных , файлов журналов и в научных приложениях.
СОДЕРЖАНИЕ
Преимущества
Преимущество разреженных файлов заключается в том, что хранилище выделяется только тогда, когда это действительно необходимо: дисковое пространство сохраняется, и большие файлы могут быть созданы, даже если в файловой системе недостаточно свободного места. Это также сокращает время первой записи, поскольку системе не нужно выделять блоки для «пропущенного» пространства. Если начальное выделение требует записи всех нулей в пространство, это также избавляет систему от необходимости дважды перезаписывать «пропущенное» пространство.
Например, для образа виртуальной машины с максимальным размером 100 ГБ, на котором фактически записано 2 ГБ файлов, потребуются полные 100 ГБ при поддержке предварительно выделенного хранилища и только 2 ГБ для разреженного файла. Если файловая система поддерживает перфорацию и гостевая операционная система выдает команды TRIM , удаление файлов в гостевой системе соответственно уменьшит необходимое пространство.
Недостатки
Недостатки в том, что разреженные файлы могут стать фрагментированными ; отчеты о свободном пространстве файловой системы могут вводить в заблуждение; заполнение файловых систем, содержащих разреженные файлы, может иметь неожиданные последствия (например, ошибки переполнения диска или превышения квоты при простой перезаписи существующей части файла, которая оказалась разреженной); и копирование разреженного файла с помощью программы , которая явно не поддерживает их, может скопировать весь несжатый размер файла, включая нулевые разделы, которые не размещены на диске, теряя преимущества свойства разреженности в файле. Разреженные файлы также полностью не поддерживаются всеми программами и приложениями для резервного копирования. Однако реализация VFS обошла два предыдущих недостатка. Загрузка исполняемых файлов в 32-битной Windows (exe или dll), которые являются разреженными, занимает гораздо больше времени, поскольку файл не может быть отображен в памяти в ограниченном адресном пространстве 4 ГБ и не кэшируется, поскольку отсутствует кодовый путь для кэширования 32-битных разреженных исполняемых файлов (Windows на 64-битные архитектуры могут отображать разреженные исполняемые файлы). В NTFS разреженный файл (а точнее его ненулевые области) не может быть сжат. NTFS реализует разреженность как особый вид сжатия, поэтому файл может быть разреженным или сжатым.
Разреженные файлы в Unix
Разреженные файлы обычно обрабатываются прозрачно для пользователя. Но в некоторых ситуациях различия между обычным файлом и разреженным файлом становятся очевидными.
Творчество
создаст файл размером пять мебибайт , но без данных, хранящихся на диске (только метаданные ). ( GNU dd имеет такое поведение, потому что он вызывает ftruncate установку размера файла; другие реализации могут просто создать пустой файл.)
Аналогичным образом можно использовать команду truncate, если она доступна:
В Linux существующий файл можно преобразовать в разреженный:
Увы, портативного способа пробивать отверстия нет; системный вызов — fallocate (FALLOC_FL_PUNCH_HOLE) в Linux, fcntl (F_FREESP) в Solaris .
Обнаружение
-s Вариант из ls команды показывает занятое пространство в блоках.
В качестве альтернативы du команда печатает занимаемое пространство, а ls печатает видимый размер. В некоторых нестандартных версиях du опция —block-size=1 печатает занятое пространство в байтах вместо блоков, чтобы его можно было сравнить с ls выводом:
Кроме того, инструмент filefrag из e2fsprogs пакета можно использовать для отображения деталей распределения блоков в файле.
Копирование
Обычно версия GNU cp хорошо определяет, является ли файл разреженным, поэтому
создает новый файл, который будет разреженным. Однако у GNU cp есть —sparse опция. Это особенно полезно, если файл, содержащий длинные нулевые блоки, сохраняется не разреженным (т.е. нулевые блоки были записаны на диск полностью). Место на диске можно сэкономить, выполнив:
Некоторые реализации cp, такие как cp во FreeBSD , не поддерживают эту —sparse опцию и всегда будут расширять разреженные файлы. Частично жизнеспособная альтернатива в этих системах — использовать rsync с собственной —sparse опцией вместо cp. К сожалению, —sparse нельзя комбинировать с —inplace .
Источник
Работа с разреженными наборами данных в пандах и склеарне
Дата публикации Nov 5, 2019
В машинном обучении есть несколько параметров, в которых мы встречаемся с разреженными наборами данных. Ниже приведены некоторые примеры:
- Пользовательский рейтинг для систем рекомендаций
- Пользователь нажимает для рекомендации по содержанию
- Векторы документов в обработке естественного языка

Разреженные наборы данных часто бывают большими, что затрудняет использование стандартных инструментов Python машинного обучения, таких как pandas и sklearn. Нередко памяти среднего локального компьютера недостаточно для хранения или обработки большого набора данных. Даже если памяти достаточно, время обработки может значительно увеличиться.
В этой статье мы дадим несколько простых советов, которым мы можем следовать при работе с большими разреженными наборами данных в python для проектов машинного обучения.
Что такое разреженная матрица?
Разреженная матрица — это матрица, в которой большинство элементов равно нулю. Напротив, таблица, в которой большинство элементов отличны от нуля, называется плотной. Мы определяем разреженность матрицы как число нулевых элементов, деленное на общее количество элементов. Матрица с разреженностью больше 0,5 является разреженной матрицей.
Работа с разреженной матрицей как плотной часто неэффективна, что приводит к чрезмерному использованию памяти.
При работе с разреженными матрицами рекомендуется использовать выделенные структуры данных для эффективного хранения и обработки. Мы будем ссылаться на некоторые из доступных структур в Python в следующих разделах.
Часто мы начинаем с плотного набора данных, который включает категориальные переменные. Как правило, мы должны применить горячее кодирование для этих переменных. Когда эти переменные имеют большую мощность (большое количество различных значений), одноразовое кодирование будет генерировать разреженный набор данных.
пример
Рассмотрим следующую таблицу с оценками пользователей для фильмов

где «Рейтинг» — это целевая переменная для задачи классификации нескольких классов.
А теперь представьте, что мы хотим обучить классификатор Факторизационных машин. Факторизационные машины (ФМ) являются основным предиктором, способным хорошо работать в задачах с высокой разреженностью, таких как рекомендательные системы. Согласно оригиналубумаганам нужно преобразовать набор данных в следующий формат:

В вышеприведенных структурах оба входных атрибута (пользователи и фильмы) кодируются в горячем виде. В пандах это простое преобразование в одну строку. Тем не менее, в случае больших наборов данных это может быть довольно громоздким.
Ниже мы продемонстрируем некоторые способы, которые облегчают преобразование и обработку таких наборов данных в pandas и sklearn.
Набор данных
Мы будем использоватьMovieLens 100Kобщедоступный набор данных, доступныйВот, Учебный файл содержит 100 000 оценок 943 пользователей по 1682 предметам. Для объема этого анализа мы будем игнорироватьотметка времениколонка.
Давайте загрузим данные в кадр данных pandas.

Горячее кодирование
Предполагая, что мы хотим преобразовать этот набор данных в формат, показанный в разделе выше, мы должны горячо закодировать столбцыИдентификатор пользователяа такжеitem_id, Для преобразования мы будем использоватьget_dummiesфункция панд, которая преобразует категориальные переменные в переменные индикатора.
Прежде чем применить преобразование, давайте проверим использование памяти в нашем исходном фрейме данных. Для этого мы будем использоватьиспользование памятифункция панд.
Теперь давайте применим преобразование и проверим использование памяти преобразованным фреймом данных.
После горячего кодирования мы создали один двоичный столбец для каждого пользователя и один двоичный столбец для каждого элемента. Таким образом, размер нового фрейма данных составляет 100.000 * 2.626, включая целевой столбец.

Мы видим, что использование памяти преобразованного фрейма данных значительно больше по сравнению с оригиналом. Это ожидается, поскольку мы увеличили количество столбцов фрейма данных. Тем не менее, большинство элементов в новом фрейме данных являются нулями.
Совет 1: Используйте разреженные структуры Pandas для хранения разреженных данных
Панды Разреженные Структуры
Pandas предоставляет структуры данных для эффективного хранения разреженных данных. В этих структурах нулевые значения (или любое другое указанное значение) фактически не сохраняются в массиве.
Хранение только ненулевых значений и их положений является распространенным методом хранения разреженных наборов данных.
Мы можем использовать эти структуры, чтобы уменьшить использование памяти нашим набором данных. Вы можете думать об этом как о способе «сжатия» фрейма данных.
В нашем примере мы преобразуем закодированные столбцыразрежённый массивs, которые представляют собой 1-й массив, в котором хранятся только ненулевые значения.
Если мы проверимdtypesнового фрейма данных мы видим, что преобразованные столбцы теперь имеют типРазреженный [uint8, 0], Это означает, что нулевые значения не сохраняются, а ненулевые значения сохраняются какuint8, D-тип ненулевых элементов может быть установлен при преобразовании вразрежённый массив
Кроме того, мы видим, что нам удалось значительно сократить использование памяти нашего фрейма данных.
До сих пор нам удалось уменьшить использование памяти фрейма данных, но для этого мы сначала создали большой фрейм данных в памяти.
Совет 2: Используйте разреженный параметр в пандах get_dummies
Можно создать разреженный фрейм данных напрямую, используяредкийпараметр в пандахget_dummies, Этот параметр по умолчаниюЛожь, ЕслиПравдазакодированные столбцы возвращаются какразрежённый массив, Установивразреженный = Trueмы создаем разреженный фрейм данных напрямую, без предварительного плотного фрейма данных в памяти.
Использование опции разреженности в кодировании в одно касание делает наш рабочий процесс более эффективным с точки зрения использования памяти и скорости.
Давайте продолжим разделять входные и целевые переменные. Мы создадим два набора векторов X, y, используя для сравнения плотные и разреженные фреймы данных.
Сплит X, у
Поезд-тест сплит и обучение модели
Далее мы переходим кsklearnвыполнить разделение на обучающие тесты на наших наборах данных и обучить модель логистической регрессии. Хотя мы использовали Факторизационные машины в качестве эталонной модели для создания нашего обучающего набора, здесь мы будем обучать простую модель логистической регрессии в sklearn только для демонстрации различий в памяти и скорости среди плотных и разреженных наборов данных. Советы, которые мы обсудим в этом примере, можно перенести в реализации Python FM, такие какxlearn,
Мы замечаем, что хотяX_sparseменьше, обработка заняла больше времени по сравнению с плотнымИкс, Причина в том, что sklearn не обрабатывает разреженные фреймы данных как таковые, согласно обсуждениюВот, Вместо этого разреженные столбцы перед обработкой преобразуются в плотные, что приводит к увеличению размера фрейма данных.
Следовательно, уменьшение размера, достигнутое до сих пор с использованием разреженных типов данных, не может быть напрямую перенесено в sklearn. В этот момент мы можем использовать разреженные разреженные форматы и преобразовать наш фрейм данных панд в скудную разреженную матрицу.
Совет 3: Преобразовать в скудную разреженную матрицу
Scipy разреженные матрицы
Пакет Scipy предлагает несколько типов разреженных матриц для эффективного хранения. Sklearn и другие пакеты машинного обучения, такие как imblearn, принимают разреженные матрицы в качестве входных данных. Поэтому при работе с большими разреженными наборами данных настоятельно рекомендуется преобразовать наш фрейм данных Pandas в разреженную матрицу, прежде чем передавать его в sklearn.
В этом примере мы будем использоватьлила такжексоформаты. В документах Scipy вы можете увидеть преимущества и недостатки каждого формата. Для эффективного построения матрицы рекомендуется использовать либоdok_matrixилиlil_matrix, [источник]
Ниже мы определяем функцию для преобразования фрейма данных в скудную разреженную матрицу. Мы начнем с построениялилматрица по столбцам, а затем преобразовать его вксо,
Давайте повторим разделение тестовых поездов и обучение модели с помощью матрицы CSR.
Как train_test_split, так и обучение модели были значительно быстрее при использованииX_sparse, Таким образом, мы заключаем, что работа с разреженной матрицей является наиболее эффективным вариантом.
Преимущество разреженных матриц будет еще более очевидным в больших наборах данных или наборах данных с большей разреженностью.
Источник


