- 1000 знаков – это сколько страниц?
- 1000 знаков – это сколько слов?
- 1000 печатных знаков – это сколько страниц?
- Текст в 1000 знаков: пример
- Выводы
- Размер символа
- в чём измеряется размер символов?
- Калькулятор Символы — Слова — Страницы
- 500, 1000, 2500 и Больше Символов — Сколько Это Слов
- 1000 — 100 000, 1 Миллион Символов — Сколько Это Страниц
- 4.11 – Символы
- Инициализация переменных char
- Печать переменных типа char
- Печать переменных char как целых чисел через приведение типов
- Ввод символов
- Размер, диапазон и символ по умолчанию у переменных char
- Экранированные последовательности
- Новая строка ( \n ) против std::endl
- В чем разница между заключением символов в одинарные и двойные кавычки?
- А как насчет других типов символов, wchar_t , char16_t и char32_t ?
1000 знаков – это сколько страниц?
1000 знаков (символов) – это принятая в копирайтинге единица измерения объёма текста. 1 000 символов также называют килознаком. От количества килознаков в вашей статье зависит величина гонорара.
Опытный копирайтер знает, сколько времени у него уходит на написание килознака, поэтому может легко рассчитать, целесообразно ли ему браться за конкретный заказ. Новичку сложнее: он-то наверняка привык мерить текст страницами, как учат в плохих университетах. Эта статья поможет начинающему копирайтеру сделать вывод: много это или мало – 1000 знаков?
1000 знаков – это сколько слов?
Мой метод быстро посчитать количество слов таков: добавь к числу знаков половинку и убери последнюю цифру. То есть к тысяче добавляем ещё 500 и удаляем нолик на конце.
Вот и получается, что 1 000 символов – это примерно 150 слов. По факту от 150 до 165. Но это, разумеется, не универсальный расчёт. Если в вашем тексте сплошь междометия (ох! ах!) или, скажем, много цифр (каждое число считается за слово), количество слов в килознаке может достичь и 200.
1000 печатных знаков – это сколько страниц?
Ставить подобный вопрос некорректно, поскольку входных данных очень мало. Сколько места займёт килознак, зависит от:
- Кегля. Очевидно, что если писать 14 шрифтом, текст займёт больше места, чем если используешь 11-й (стоит в Ворде по умолчанию). Шрифта. Размер букв во встроенных шрифтах текстовых редакторов тоже отличается. Например, 4 строчки, написанные Times New Roman, превратятся в 3 строчки, если перевести текст в Monotype Corsiva. Междустрочного интервала. И других параметров разметки страницы – вроде величины отступов. Количества списков. Плохие копирайтеры часто грешат тем, что превращают статьи в большущие списки – якобы ради повышения читабельности. В этом случае и 1 килознак может оказаться растянут на 2-2.5 листа. От способа расчета (без пробелов, с пробелами). Если считать с пробелами, объём текста в символах примерно на 15% выше. Размера страницы (формата). В редакторе Word можно менять формат. По умолчанию стоит А4 (21 см × 29.7 см). Страницы формата А5 (например) куда меньше. Настраивается размер в «Панели инструментов» Word – вкладка «Разметка страницы», раздел «Размер».
Текст в 1000 знаков: пример
Делюсь с вами примером собственноручно написанной рецензии на книгу. На иллюстрации один килознак 14 шрифтом на листе формата А4. Картинки кликабельны.
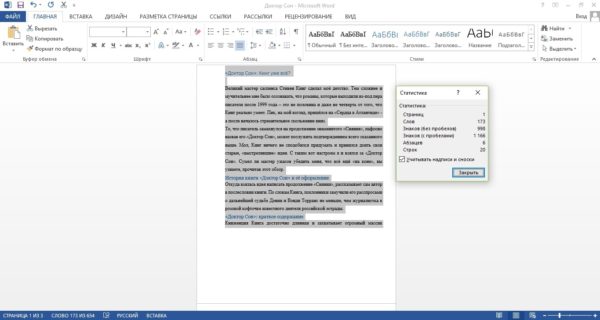
А вот так выглядит тот же текст 11 шрифтом Calibri:
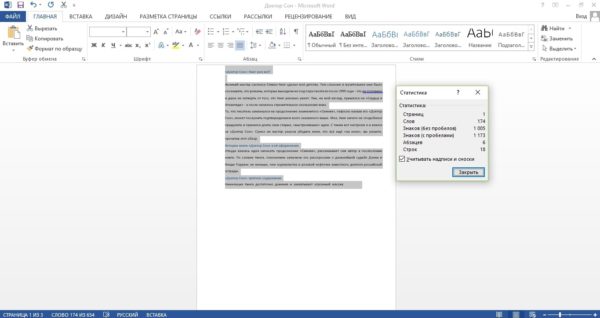
То есть если писать 11 кеглем, килознак занимает примерно половину листа.
Выводы
Приведу краткие выводы по статье:
- 1 000 символов – это примерно 150 слов. 1 000 знаков 14 шрифтом – это около 2/3 листа. Тысячезнак, набранный 11 кеглем – около ½ страницы.
Надеюсь, после такой вот конвертации вы сможете посчитать, сколько времени уйдёт на написание 1000 символов, и уже на основе этих расчётов решить, выгодно ли вам заниматься копирайтингом.
А сколько ты тратишь времени на написание 1 кз? Скорее рассказывай в комментариях, как организуешь работу! Делись своими успехами в тайм-менеджменте, ведь это безумно интересно!
Источник
Размер символа




![]()
![]()
Символ также характеризуется таким параметром как его размер. Размер символов измеряется в пунктах. Пунктом принято называть единицу измерения длины равную 1/72 дюйма, что соответствует 0.352мм. В большинстве документов для основного текста обычно используются размеры шрифтов в интервале от 8 до 14 пунктов, то есть приблизительно от 3 до 5 мм. Также, для заголовков и в других особых случаях, можно использовать как большие, так и меньшие размеры шрифтов.
Размер символов должен быть согласован с форматом страницы, так как он зависит от размера страницы, ширины колонок, назначения текста и типа шрифта. Для формата А4, который имеют обычные листы бумаги, применяют шрифты размером 12-14 пунктов. Для страниц меньшего формата — 10 пунктов. Дополнительный текст, такой как примечания, врезки, подрисуночные надписи, выполняют уменьшенным шрифтом, по сравнению с размером символов основного текста. На мелких шрифтах засечки букв плохо просматриваются, и для дополнительного текста часто применяют простой шрифт без засечек.
Тип начертания символа
Третьей из характеристик символа является тип его начертания. Под начертанием символа понимается изменение способа его представления.
Используется следующие типы начертания:
— полужирное начертание применяют в заголовках всех уровней и крайне редко в основном тексте для акцентирования внимания на особо важной информации;
— курсивное начертание используют в заголовках и в основном тексте, например, для выделения терминов и понятий;
— подчеркивание символов предназначено также для акцентирования внимания на важной информации и для выделения текста в электронных документах, распространяющихся по компьютерным сетям. Для специального подчеркивания символов можно использовать дополнительные варианты: двойная линия, только слова, пунктирная и штриховая линии и ряд других вариантов подчеркивания.
Источник
в чём измеряется размер символов?
Существуют две системы типографских измерений: англо-американская система, или система Пика (Pica), и система Дидо (Didot).
Система Пика применяется в Великобритании, Америке и в большинстве стран остального мира, кроме континентальной Европы. Система Дидо применяется в большинстве стран континентальной Европы и в России. В обеих системах основной единицей измерения является типографский пункт (point); но в то время как в англо-американской системе он равен округленно 0,351 мм, пункт в системе Дидо чуть больше – округленно 0,376 мм.
Величина шрифта в наборе выражается в кеглях. Размер кегля определяется в пунктах. Поскольку эти понятия складывались во времена металлического набора, кеглем считается величина площадки, на которой размещается буква (знак) . Например, кегль 10 пунктов равен 3,76 мм (3,51 мм в системе Пика) , но само очко знака, естественно, меньше, так как необходимо предусмотреть место для надстрочных и подстрочных элементов знака (диакритических знаков) .
Профессиональные наименования кеглей различного размера широко употребляются до сих пор в типографском деле и фигурируют в специальной литературе:
кегль 3 пункта – бриллиант
кегль 4 пункта – диамант;
кегль 6 пунктов – нонпарель;
кегль 7 пунктов – миньон;
кегль 8 пунктов – петит;
кегль 9 пунктов – боргес;
кегль 10 пунктов – корпус;
кегль 12 пунктов – цицеро;
кегль 14 пунктов – миттель.
Источник
Калькулятор Символы — Слова — Страницы
В работе с текстами мы каждый день сталкиваемся с потребностью считать, сколько тот или иной объем текста занимает страниц, а еще важно понять объем символов и слов, как в одном направлении подсчета, так и в обратном. 1000 знаков — это сколько слов и страниц, сколько знаков на странице находится в документе ворда и т. д.
Для того чтобы сделать любые расчеты было легко и мгновенно онлайн как с пробелами, так и без пробелов, мы сделали калькулятор (конвертор) абсолютно бесплатно, найти его можете на этой странице + сделали для вас удобные таблицы ниже с примерами.
Мы приводим расчеты при размерах шрифта (кегль) 11 — 12 по стандартам Word. Данные в таблицах ниже даны для ознакомления и зависят от размера вашего шрифта, количества слов, оформления текста, других параметров.
500, 1000, 2500 и Больше Символов — Сколько Это Слов
На каждый запрос мы сделали свой пример и разместили его в таблице. Теперь можно не тратить время, чтобы узнать, как посчитать это в ворде, потому что есть наш онлайн-сервис и таблица ниже.
| Количество символов с пробелами | Количество слов (приблизительно) |
| 500 символов — это сколько слов | 85 |
| 1000 символов — это сколько слов | 170 |
| 1500 символов — это сколько слов | 255 |
| 2000 символов — это сколько слов | 340 |
| 2500 символов — это сколько слов | 425 |
| 5000 символов — это сколько слов | 850 |
| 10 000 символов — это сколько слов | 1700 |
| 15 000 символов — это сколько слов | 2550 |
| 20 000 символов — это сколько слов | 3400 |
| 25 000 символов — это сколько слов | 4250 |
| 50 000 символов — это сколько слов | 8500 |
| 100 000 символов — это сколько слов | 17000 |
1000 — 100 000, 1 Миллион Символов — Сколько Это Страниц
Когда мы в интернете встречали статьи с ответом на вопрос, сколько символов на странице, и что одна страница А4 — это 1800 знаков (это около 2000 символов с пробелами), мы не сильно понимали, откуда они взяли такую цифру.
Мы работаем в сфере копирайтинга несколько лет и знаем, что 2500 символов с пробелами — это одна страница (и это около 2200 символов без пробелов, но никак не меньше).
Ниже в таблице мы привели самые популярные запросы по таким расчетам, а если хотите посчитать онлайн самостоятельно и не искать уже больше информацию, сколько символов содержит страница — просто переходите на главную ИНтексти.
| Количество символов с пробелами | Количество страниц (приблизительно) |
| 500 символов — это сколько страниц | 0,2 |
| 1000 символов — это сколько страниц | 0,4 |
| 1500 символов — это сколько страниц | 0,6 |
| 2000 символов — это сколько страниц | 0,8 |
| 2500 символов — это сколько страниц | 1 страница |
| 3000 символов — это сколько страниц | 1,25 |
| 4000 символов — это сколько страниц | 1,75 |
| 5000 символов — это сколько страниц | 2 |
| 6000 символов — это сколько страниц | 2,5 |
| 7000 символов — это сколько страниц | 3 |
| 8000 символов — это сколько страниц | 3,25 |
| 10 000 символов — это сколько страниц | 4 страницы |
| 12 000 символов — это сколько страниц | 5 |
| 15 000 символов — это сколько страниц | 6 |
| 20 000 символов — это сколько страниц | 8 |
| 25 000 символов — это сколько страниц | 10 |
| 30 000 символов — это сколько страниц | 12 |
| 50 000 символов — это сколько страниц | 20 |
| 70 000 символов — это сколько страниц | 28 |
| 100 000 символов — это сколько страниц | 40 страниц |
| 200 000 символов — это сколько страниц | 80 |
| 250 000 символов — это сколько страниц | 100 |
| 500 000 символов — это сколько страниц | 200 |
| 1 000 000 символов — это сколько страниц | 400 страниц |
Теперь на одном онлайн-ресурсе вы можете сделать полный анализ текста, в том числе узнать ХХХ символов — сколько это слов и страниц. Сохраняйте в закладки или запоминайте названием INtexty и заходите каждый день для своей перепроверки!
Понравился наш бесплатный сервис? — Поставь высокую оценку и поделись с друзьями в соцсетях!
Источник
4.11 – Символы
На данный момент базовые типы данных, которые мы рассмотрели, использовались для хранения чисел (целые числа и числа с плавающей запятой) или значений истина/ложь (логические значения). Но что, если мы хотим хранить буквы?
Для хранения символов был разработан тип данных char . Символом может быть одна буква, цифра, знак или пробел.
Тип данных char является целочисленным типом, что означает, что базовое значение хранится как целое число. Подобно тому, как логическое значение 0 интерпретируется как false , а ненулевое значение интерпретируется как true , целое число, хранимое переменной char , интерпретируется как символ ASCII.
ASCII расшифровывается как American Standard Code for Information Interchange (Американский стандартный код для обмена информацией) и определяет конкретный способ представления английских символов (плюс несколько других символов) в виде чисел от 0 до 127 (называемых кодом ASCII или кодовым обозначением). Например, код ASCII 97 интерпретируется как символ ‘ а ‘.
Символьные литералы всегда помещаются в одинарные кавычки (например, ‘ g ‘, ‘ 1 ‘, ‘ ‘).
Ниже приведена полная таблица символов ASCII:
| Code | Symbol | Code | Symbol | Code | Symbol | Code | Symbol |
|---|---|---|---|---|---|---|---|
| 0 | NUL (null) | 32 | (space) | 64 | @ | 96 | ` |
| 1 | SOH (start of header, начало «заголовка») | 33 | ! | 65 | A | 97 | a |
| 2 | STX (start of text, начало «текста») | 34 | ” | 66 | B | 98 | b |
| 3 | ETX (end of text, конец «текста») | 35 | # | 67 | C | 99 | c |
| 4 | EOT (end of transmission, конец передачи) | 36 | $ | 68 | D | 100 | d |
| 5 | ENQ (enquiry, «Прошу подтверждения!») | 37 | % | 69 | E | 101 | e |
| 6 | ACK (acknowledge, «Подтверждаю!») | 38 | & | 70 | F | 102 | f |
| 7 | BEL (bell, звуковой сигнал: звонок) | 39 | ’ | 71 | G | 103 | g |
| 8 | BS (backspace, возврат на один символ) | 40 | ( | 72 | H | 104 | h |
| 9 | HT (horizontal tab, горизонтальная табуляция) | 41 | ) | 73 | I | 105 | i |
| 10 | LF (line feed/new line, перевод строки) | 42 | * | 74 | J | 106 | j |
| 11 | VT (vertical tab, вертикальная табуляция) | 43 | + | 75 | K | 107 | k |
| 12 | FF (form feed / new page, «прогон страницы», новая страница) | 44 | , | 76 | L | 108 | l |
| 13 | CR (carriage return, возврат каретки) | 45 | — | 77 | M | 109 | m |
| 14 | SO (shift out, «Переключиться на другую ленту (кодировку)») | 46 | . | 78 | N | 110 | n |
| 15 | SI (shift in, «Переключиться на исходную ленту (кодировку)») | 47 | / | 79 | O | 111 | o |
| 16 | DLE (data link escape, «Экранирование канала данных») | 48 | 0 | 80 | P | 112 | p |
| 17 | DC1 (data control 1, первый символ управления устройством) | 49 | 1 | 81 | Q | 113 | q |
| 18 | DC2 (data control 2, второй символ управления устройством) | 50 | 2 | 82 | R | 114 | r |
| 19 | DC3 (data control 3, третий символ управления устройством) | 51 | 3 | 83 | S | 115 | s |
| 20 | DC4 (data control 4, четвертый символ управления устройством) | 52 | 4 | 84 | T | 116 | t |
| 21 | NAK (negative acknowledge, «Не подтверждаю!») | 53 | 5 | 85 | U | 117 | u |
| 22 | SYN (synchronous idle) | 54 | 6 | 86 | V | 118 | v |
| 23 | ETB (end of transmission block, конец текстового блока) | 55 | 7 | 87 | W | 119 | w |
| 24 | CAN (cancel, «Отмена») | 56 | 8 | 88 | X | 120 | x |
| 25 | EM (end of medium, «Конец носителя») | 57 | 9 | 89 | Y | 121 | y |
| 26 | SUB (substitute, «Подставить») | 58 | : | 90 | Z | 122 | z |
| 27 | ESC (escape) | 59 | ; | 91 | [ | 123 | < |
| 28 | FS (file separator, разделитель файлов) | 60 | 94 | ^ | 126 | ||
| 31 | US (unit separator, разделитель юнитов) | 63 | ? | 95 | _ | 127 | DEL (delete, стереть последний символ) |
Коды 0–31 называются непечатаемыми символами и в основном используются для форматирования и управления принтерами. Большинство из них сейчас устарели.
Коды 32–127 называются печатными символами и представляют собой буквы, цифры и знаки препинания, которые большинство компьютеров используют для отображения основного английского текста.
Инициализация переменных char
Вы можете инициализировать переменные типа char , используя символьные литералы:
Вы также можете инициализировать переменные типа char целыми числами, но этого, если возможно, следует избегать.
Предупреждение
Будьте осторожны, чтобы не перепутать символы чисел с целыми числами. Следующие две инициализации не эквивалентны:
Символы чисел предназначены для использования, когда мы хотим представить числа в виде текста, а не в виде чисел и применения к ним математических операций.
Печать переменных типа char
При использовании std::cout для печати переменной типа char , std::cout выводит переменную char как символ ASCII:
Данная программа дает следующий результат:
Мы также можем напрямую выводить символьные литералы:
В результате это дает:
Напоминание
В C++ целочисленный тип фиксированной ширины int8_t обычно обрабатывается так же, как signed char , поэтому он обычно печатается как символ ( char ) вместо целого числа.
Печать переменных char как целых чисел через приведение типов
Если мы хотим вывести char как число вместо символа, мы должны указать std::cout , чтобы он печатал переменную char , как если бы она была целочисленного типа. Один (плохой) способ сделать это – присвоить значение переменной char другой переменной целочисленного типа и напечатать эту переменную:
Однако это довольно коряво. Лучше использовать приведение типа. Приведение типа создает значение одного типа из значения другого типа. Для преобразования между базовыми типами данных (например, из char в int или наоборот) мы используем приведение типа, называемое статическим приведением.
Синтаксис статического приведения выглядит немного забавным:
static_cast принимает значение из выражения в качестве входных данных и преобразует его в любой базовый тип, который представляет новый_тип (например, int , bool , char , double ).
Ключевые выводы
Всякий раз, когда вы видите синтаксис C++ (за исключением препроцессора), в котором используются угловые скобки, то, что между угловыми скобками, скорее всего, будет типом. Обычно C++ работает с концепциями, которым нужен параметризуемый тип.
Ниже показан пример использования статического приведения для создания целочисленного значения из нашего значения char :
Эта программа дает следующий вывод:
Важно отметить, что параметр static_cast вычисляется как выражение. Когда мы передаем переменную, эта переменная вычисляется для получения ее значения, которое затем преобразуется в новый тип. На переменную не влияет приведение ее значения к новому типу. В приведенном выше случае переменная ch по-прежнему является char и сохраняет то же значение.
Также обратите внимание, что статическое приведение не выполняет никакой проверки диапазона значений, поэтому, если вы приведете большое целое число в char , вы вызовете переполнение своей переменной char .
О статическом приведении типов и других типах приведения мы поговорим подробнее в следующем уроке (8.5 – Явное преобразование типов (приведение) и static_cast ).
Ввод символов
Следующая программа просит пользователя ввести символ, а затем печатает его как символ и его код ASCII:
Ниже показан результат одного запуска:
Обратите внимание, что std::cin позволяет вводить несколько символов. Однако переменная ch может содержать только 1 символ. Следовательно, в переменную ch извлекается только первый входной символ. Остальная часть пользовательского ввода остается во входном буфере, который использует std::cin , и может быть извлечена с помощью последующих вызовов std::cin .
Вы можете увидеть это поведение в следующем примере:
Размер, диапазон и символ по умолчанию у переменных char
char определяется C++ всегда размером 1 байт. По умолчанию char может быть со знаком или без знака (хотя обычно он со знаком). Если вы используете переменные char для хранения символов ASCII, вам не нужно указывать знак (поскольку переменные char со знаком и без знака могут содержать значения от 0 до 127).
Если вы используете char для хранения небольших целых чисел (чего не следует делать, если вы явно не оптимизируете используемую память), вы всегда должны указывать, со знаком переменная или нет. signed char (со знаком) может содержать число от -128 до 127. unsigned char (без знака) может содержать число от 0 до 255.
Экранированные последовательности
В C++ есть некоторые символы, которые имеют особое значение. Эти символы называются экранированными последовательностями (управляющими последовательностями, escape-последовательностями). Экранированная последовательность начинается с символа ‘\’ (обратный слеш), за которым следует буква или цифра.
Вы уже видели наиболее распространенную экранированную последовательность: ‘ \n ‘, которую можно использовать для вставки символа новой строки в текстовую строку:
Эта программа выдает:
Еще одна часто используемая экранированная последовательность – ‘ \t ‘, которая включает горизонтальную табуляцию:
Три других примечательных экранированных последовательности:
- \’ – печатает одинарную кавычку;
- \» – печатает двойную кавычку;
- \\ – печатает обратный слеш.
Ниже приведена таблица всех экранированных последовательностей:
| Название | Символ | Назначение |
|---|---|---|
| Предупреждение | \a | Выдает предупреждение, например звуковой сигнал |
| Backspace | \b | Перемещает курсор на одну позицию назад |
| Перевод страницы | \f | Перемещает курсор на следующую логическую страницу |
| Новая строка | \n | Перемещает курсор на следующую строку |
| Возврат каретки | \r | Перемещает курсор в начало строки |
| Горизонтальная табуляция | \t | Печать горизонтальной табуляции |
| Вертикальная табуляция | \v | Печатает вертикальную табуляцию |
| Одинарная кавычка | \’ | Печать одинарной кавычки |
| Двойная кавычка | \» | Печать двойной кавычки |
| Обратная косая черта | \\ | Печатает обратный слеш |
| Вопросительный знак | \? | Печатает вопросительный знак Больше не актуально. Вы можете использовать вопросительные знаки без экранирования. |
| Восьмеричное число | \(число) | Преобразуется в символ, представленный восьмеричным числом |
| Шестнадцатеричное число | \x(число) | Преобразуется в символ, представленный шестнадцатеричным числом |
Вот несколько примеров:
Эта программа напечатает:
Новая строка ( \n ) против std::endl
В чем разница между заключением символов в одинарные и двойные кавычки?
Отдельные символы всегда заключаются в одинарные кавычки (например, ‘a’, ‘+’, ‘5’). char может представлять только один символ (например, букву а, знак плюса, цифру 5). Что-то вроде этого некорректно:
Текст, заключенный в двойные кавычки (например, «Hello, world!»), называется строкой. Строка – это набор последовательных символов (и, таким образом, строка может содержать несколько символов).
Пока вы можете использовать строковые литералы в своем коде:
Мы обсудим строки в следующем уроке (4.12 – Знакомство с std::string ).
Правило
Всегда помещайте отдельные символы в одинарные кавычки (например, ‘ t ‘ или ‘ \n ‘, а не » t » или » \n «). Это помогает компилятору более эффективно выполнять оптимизацию.
А как насчет других типов символов, wchar_t , char16_t и char32_t ?
wchar_t следует избегать почти во всех случаях (за исключением взаимодействия с Windows API). Его размер определяется реализацией и не является надежным. Он не рекомендуется для использования.
В качестве отступления.
Англоязычный термин «deprecated» (не рекомендуется) означает «всё еще поддерживается, но больше не рекомендуется для использования, потому что он был заменен чем-то лучшим или больше не считается безопасным».
Подобно тому, как ASCII сопоставляет целые числа 0–127 с символами английского алфавита, существуют и другие стандарты кодировки символов для сопоставления целых чисел (разного размера) с символами других языков. Наиболее известной кодировкой за пределами диапазона ASCII является стандарт Unicode (Юникод), который сопоставляет более 110 000 целых чисел с символами на многих языках. Поскольку Unicode содержит очень много кодовых обозначений, то для одного кодового обозначения, чтобы представить один символ, Unicode требуется 32 бита (кодировка UTF-32). Однако символы Unicode также могут быть закодированы с использованием 16-ти или 8-ми битов (кодировки UTF-16 и UTF-8 соответственно).
char16_t и char32_t были добавлены в C++11 для обеспечения явной поддержки 16-битных и 32-битных символов Unicode. char8_t был добавлен в C++20.
Если вы не планируете сделать свою программу совместимой с Unicode, вам не нужно использовать char8_t , char16_t или char32_t . Юникод и локализация в основном выходят за рамки этих руководств, поэтому мы не будем рассматривать их дальше.
А пока при работе с символами (и строками) вы должны использовать только символы ASCII. Использование символов из других наборов символов может привести к неправильному отображению ваших символов.
Источник


