- ОБОБЩЕНИЕ ДАННЫХ
- Смотреть что такое «ОБОБЩЕНИЕ ДАННЫХ» в других словарях:
- обобщение данных
- Смотреть что такое «обобщение данных» в других словарях:
- 4. Обобщения
- Читайте также
- Отношение обобщения
- Отношение обобщения
- ГЛАВА 10. Обобщения
- Совет 37. Используйте accumulate или for_each для обобщения интервальных данных
- 4. Обобщения
- Уровень обобщения базы данных
- Введение
- Постановка проблемы
- От частного к общему
- Минимальное обобщение
ОБОБЩЕНИЕ ДАННЫХ
Делопроизводство и архивное дело в терминах и определениях. — М.: Флинта : Наука . С. Ю. Кабашов, И. Г. Асфандиярова . 2009 .
Смотреть что такое «ОБОБЩЕНИЕ ДАННЫХ» в других словарях:
обобщение данных — Технологическая операция, в результате которой из исходных данных получают новые данные уменьшенного объема. [ГОСТ Р 51170 98 ] Тематики качество служебной информации … Справочник технического переводчика
обобщение данных — 3.1.8 обобщение данных: Технологическая операция, в результате которой из исходных данных получают новые данные уменьшенного объема Источник: ГОСТ Р 51170 98: Качество служебной информации. Термины и определения оригинал документа … Словарь-справочник терминов нормативно-технической документации
обобщение данных об интенсивности отказов — — [Л.Г.Суменко. Англо русский словарь по информационным технологиям. М.: ГП ЦНИИС, 2003.] Тематики информационные технологии в целом EN failure rate synthesis … Справочник технического переводчика
обобщение данных об интенсивностях отказов — — [http://slovarionline.ru/anglo russkiy slovar neftegazovoy promyishlennosti/] Тематики нефтегазовая промышленность EN failure rate synthesis … Справочник технического переводчика
обработка данных (контроль данных; обобщение данных) — Технологические операции элементарные акты технологического процесса переработки данных, выделяемые в моделях ТППД для решения задач обеспечения качества служебной информации. Перечисленные типы технологических операций переработки данных… … Справочник технического переводчика
углубление в данные/консолидация (обобщение) данных — переход по иерархии Пользователь имеет возможность переходить вверх по направлению от детального (down) представления данных к агрегированному (up) и наоборот. Направление детализации (обобщения) может быть задано как по иерархии отдельных… … Справочник технического переводчика
обобщение — 3.34 обобщение (generalization): Особое понятие, измененное для большей степени обобщения, использования или цели, либо акт исключения или изменения деталей в рамках особого понятия (концепции) для получения его обобщения. Примечание Обобщение… … Словарь-справочник терминов нормативно-технической документации
обобщение — Процесс, посредством которого определенный опыт становится репрезентацией целого класса опыта; один из трех процессов моделирования в НЛП. Краткий толковый психолого психиатрический словарь. Под ред. igisheva. 2008. обобщение … Большая психологическая энциклопедия
обобщение — ОБОБЩЕНИЕ (англ. generalization; от лат. genero производить, порождать). 1. В логике операция порождения экзистенциальных и универсальных суждений; в дедуктивной логике на основе постулированных правил вывода для кванторов общности и… … Энциклопедия эпистемологии и философии науки
ОБОБЩЕНИЕ — (лат. generalisatio), мысленный переход: 1) от отд. фактов, событий к отождествлению их в мыслях (индуктивное обобщение); 2) от одной мысли к другой более общей (логич. О.). Эти переходы осуществляются на основе особого рода правил. Так,… … Философская энциклопедия
Источник
обобщение данных
3.1.8 обобщение данных: Технологическая операция, в результате которой из исходных данных получают новые данные уменьшенного объема
Словарь-справочник терминов нормативно-технической документации . academic.ru . 2015 .
Смотреть что такое «обобщение данных» в других словарях:
обобщение данных — Технологическая операция, в результате которой из исходных данных получают новые данные уменьшенного объема. [ГОСТ Р 51170 98 ] Тематики качество служебной информации … Справочник технического переводчика
ОБОБЩЕНИЕ ДАННЫХ — согласно ГОСТ Р 51170–98 «Качество служебной информации. Термины и определения», – технологическая операция, в результате которой из исходных данных получают новые данные уменьшенного объема … Делопроизводство и архивное дело в терминах и определениях
обобщение данных об интенсивности отказов — — [Л.Г.Суменко. Англо русский словарь по информационным технологиям. М.: ГП ЦНИИС, 2003.] Тематики информационные технологии в целом EN failure rate synthesis … Справочник технического переводчика
обобщение данных об интенсивностях отказов — — [http://slovarionline.ru/anglo russkiy slovar neftegazovoy promyishlennosti/] Тематики нефтегазовая промышленность EN failure rate synthesis … Справочник технического переводчика
обработка данных (контроль данных; обобщение данных) — Технологические операции элементарные акты технологического процесса переработки данных, выделяемые в моделях ТППД для решения задач обеспечения качества служебной информации. Перечисленные типы технологических операций переработки данных… … Справочник технического переводчика
углубление в данные/консолидация (обобщение) данных — переход по иерархии Пользователь имеет возможность переходить вверх по направлению от детального (down) представления данных к агрегированному (up) и наоборот. Направление детализации (обобщения) может быть задано как по иерархии отдельных… … Справочник технического переводчика
обобщение — 3.34 обобщение (generalization): Особое понятие, измененное для большей степени обобщения, использования или цели, либо акт исключения или изменения деталей в рамках особого понятия (концепции) для получения его обобщения. Примечание Обобщение… … Словарь-справочник терминов нормативно-технической документации
обобщение — Процесс, посредством которого определенный опыт становится репрезентацией целого класса опыта; один из трех процессов моделирования в НЛП. Краткий толковый психолого психиатрический словарь. Под ред. igisheva. 2008. обобщение … Большая психологическая энциклопедия
обобщение — ОБОБЩЕНИЕ (англ. generalization; от лат. genero производить, порождать). 1. В логике операция порождения экзистенциальных и универсальных суждений; в дедуктивной логике на основе постулированных правил вывода для кванторов общности и… … Энциклопедия эпистемологии и философии науки
ОБОБЩЕНИЕ — (лат. generalisatio), мысленный переход: 1) от отд. фактов, событий к отождествлению их в мыслях (индуктивное обобщение); 2) от одной мысли к другой более общей (логич. О.). Эти переходы осуществляются на основе особого рода правил. Так,… … Философская энциклопедия
Источник
4. Обобщения
Очередным видом связи классов сущностей между собой, который мы рассмотрим, является связь вида обобщение. Это также нерекурсивный вид связи.
Итак, связь типа обобщение реализуется как взаимосвязь одного родительского класса сущностей с несколькими дочерними классами сущностей (в отличие от предыдущей рассмотренной связи Ассоциации, в которой речь шла о нескольких родительских классах сущностей и одним дочернем классе сущностей).
При формулировании правил представления данных при помощи связи Обобщения необходимо сразу сказать, что эта взаимосвязь одного родительского класса сущностей и нескольких дочерних классов сущностей, описывается полностью идентифицирующими связями, т. е. категориальными связями. Вспоминая определение полностью идентифицирующих связей, мы приходим к выводу, что при использовании Обобщения каждый атрибут первичного ключа родительского класса сущностей переносится в состав первичного ключа классов сущностей дочерних, т. е. атрибуты первичного мигрирующего ключа родительского класса сущностей полностью формируют первичные ключи всех дочерних классов сущностей, они их идентифицируют.
Любопытно отметить, что при Обобщении реализуется так называемая иерархия категорий или иерархия наследования.
При этом родительский класс сущностей определяет класс обобщенных сущностей, характеризующийся атрибутами, общими для сущностей всех дочерних классов или так называемых категориальных сущностей т. е. родительский класс сущностей представляет собой буквальное обобщение всех своих дочерних классов сущностей.
В качестве примера реализации обобщения в реляционной модели данных построим следующую модель. Эта модель будет основана на обобщенном понятии «Учащиеся» и будет описывать следующие категориальные понятия (т. е. будет обобщать следующие дочерние классы сущностей): «Школьники», «Студенты» и «Аспиранты».
Итак, построим ключевую диаграмму, отражающую суть взаимоотношений между родительским классом сущности и дочерними классами сущностей, описываемых связью типа Обобщение.
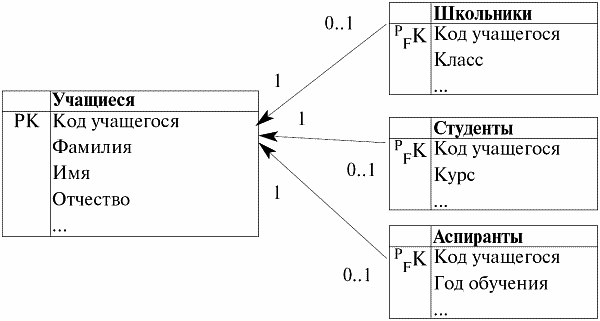
Итак, что же мы видим?
Во-первых, каждому из базовых отношений (или из классов сущностей, что одно и то же) «Школьники», «Студенты» и «Аспиранты» соответствуют свои собственные атрибуты, как то «Класс», «Курс» и «Год обучения». Каждый из этих атрибутов характеризует участников своего собственного класса сущностей. Еще мы видим, что первичный ключ родительского класса сущностей «Учащиеся» мигрирует в каждый дочерний класс сущностей и формирует там первичный внешний ключ. При помощи этих связей мы можем по коду любого учащегося определить его имя, фамилию и отчество, информацию о которых мы не найдем в самих соответствующих дочерних классах сущностей.
Во-вторых, так как мы говорим о полностью идентифицирующей (или категориальной) связи классов сущностей, то обратим внимание на кратности связей между родительским классом сущностей и его дочерними классами. На родительском конце каждой из этих связей стоит кратность «один», а на каждом дочернем конце связей стоит кратность «не более одного». Если вспомнить определение полностью идентифицирующей связи классов сущностей, то становится понятно, что действительно единственный в своем роде код учащегося, являющийся первичным ключом класса сущностей «Учащиеся», задает не более одного атрибута с таким кодом в каждом дочернем классе сущностей «Школьники», «Студенты» и «Аспиранты». Поэтому все связи имеют именно такие кратности.
Запишем фрагмент операторов создания базовых отношений «Школьники» и «Студенты» с определением правил поддержания ссылочной целостности типа cascade. Итак, имеем:
Create table Школьники
primary key (Код ученика)
foreign key (Код ученика) references Учащиеся (Код ученика)
on update cascade
on delete cascade
Create table Студенты
primary key (Код студента)
foreign key (Код студента) references Учащиеся (Код студента)
on update cascade
on delete cascade;
Таким образом, мы видим, что в дочернем классе сущностей (или отношений) «Школьники» задается первичный внешний ключ, ссылающийся на родительский класс сущностей (или отношение) «Учащиеся». Правило cascade поддержания ссылочной целостности определяет, что при удалении или при обновлении атрибутов родительского класса сущностей «Учащиеся» соответствующие им атрибуты дочернего отношения «Школьники» будут автоматически (каскадом) обновляться или удаляться. Аналогично при удалении или при обновлении атрибутов родительского класса сущностей «Учащиеся» соответствующие им атрибуты дочернего отношения «Студенты» также будут автоматически обновляться или удаляться.
Необходимо заметить, что здесь используется именно это правило поддержания ссылочной целостности, потому что в данном контексте (перечень учащихся) не рационально запрещать удаление и обновление информации, а также присваивать неопределенное значение вместо реальных сведений.
А теперь приведем пример классов сущностей, описанных в предыдущей диаграмме, только представленных в табличной форме. Итак, имеем следующие таблицы-отношения:
Учащиеся – родительское отношение, объединяющее в себе информацию об атрибутах всех остальных отношений:

Школьники – дочернее отношение:

Студенты – второе дочернее отношение:
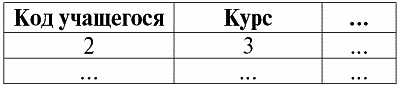
Аспиранты – третье дочернее отношение:

Итак, действительно, мы видим, что в дочерних классах сущностей не прописана информация о фамилии, имени и отчестве учащихся, т. е. школьников, студентов и аспирантов. Эту информацию можно получить только посредством ссылок на родительский класс сущностей.
Также мы видим, что различные коды учащихся в классе сущностей «Учащиеся» могут соответствовать различным дочерним классам сущностей. Так, про учащегося с кодом «1» Заботина Николая в родительском отношении неизвестно ничего, кроме его имени, а всю остальную информацию (кто он, школьник, студент или аспирант) можно узнать только обратившись к соответствующему дочернему классу сущностей (определяется по коду).
Аналогичным образом необходимо работать с остальными учащимися, чьи коды указаны в родительском классе сущностей «Учащиеся».
Данный текст является ознакомительным фрагментом.
Продолжение на ЛитРес
Читайте также
Отношение обобщения
Отношение обобщения Отношение обобщения служит для указания того факта, что некоторый вариант использования А может быть обобщен до варианта использования В. В этом случае вариант А будет являться специализацией варианта В. При этом В называется предком или родителем
Отношение обобщения
Отношение обобщения Отношение обобщения является обычным таксономическим отношением между более общим элементом (родителем или предком) и более частным или специальным элементом (дочерним или потомком). Данное отношение может использоваться для представления
ГЛАВА 10. Обобщения
ГЛАВА 10. Обобщения С появлением .NET 2.0 язык программирования C# стал поддерживать новую возможность CTS (Common Type System – общая система типов), названную обобщениями (generics). Упрощенно говоря, обобщения обеспечивают программисту возможность определения «заполнителей» (формально
Совет 37. Используйте accumulate или for_each для обобщения интервальных данных
Совет 37. Используйте accumulate или for_each для обобщения интервальных данных Иногда возникает необходимость свести целый интервал к одному числу или, в более общем случае, к одному объекту. Для стандартных задач обобщения существуют специальные алгоритмы. Так, алгоритм count
4. Обобщения
4. Обобщения Очередным видом связи классов сущностей между собой, который мы рассмотрим, является связь вида обобщение. Это также нерекурсивный вид связи.Итак, связь типа обобщение реализуется как взаимосвязь одного родительского класса сущностей с несколькими
Источник
Уровень обобщения базы данных
Несколько лет назад я попробовал сделать сайт на такой системе как MODx и мне понравилось, не смотря на опыт работы с другими CMS, а может и благодаря этому. Понравилась именно логика построения работы с ней, принципы структуры данных и многое другое, но в первую очередь, то, что фрилансеру нужно особенно часто – простота и скорость запуска проекта при высокой гибкости. Но, хотя MODx мне до сих пор по нраву, пост не совсем о ней и даже скорее совсем о другом.
Введение
На самом деле я рассматриваю эту cms только как пример, того что присутствует во многих и опенсурс, и коммерческих системах. Просто мне как фрилансеру до недавних пор приходилось работать почти всегда с разработкой сайтов по дешевле и побыстрее – может у других фрилансеров много «жирных» клиентов, я не знаю, у меня не было. Так вот такая ситуация привела к не плохому опыту работы на модыксе. Но открытие собственной компании и дальнейшее подтягивание клиентов с индивидуальными запросами, потребовало вспоминать и улучшать свой лвл в настоящем программировании и построении баз данных. И вот тут я и почувствовал какой-то дискомфорт, что ли, ну как минимум смущение при воспоминании структуры как MODx, так и некоторых других открытых систем. Далее поясняю подробнее, что именно показалось странным, но интересным.

Дело в том, что в MODx Revo основным понятием для построения структуры сайта являются ресурсы. Вот именно, там нет такого как, например, в том же Вордпрессе отдельно страницы сайта, отдельно записи блога. Все страницы и записи, и даже много чего еще реализуется через модель ресурсов сайта. На самом деле это удобно, особенно учитывая тот факт, что это cmf/cms, то есть система рассчитана на разработку совершенно разных сайтов и тематически и технически. Таким образом, за всей структурой сайта удобно следить в одной панели управления ресурсами. В общем, система ресурсов позволяет создавать и управлять следующими сущностями сайта (хотел было написать объектами, но в ООП это слово уже занято, так что пусть будет «сущности»):
• Обычные html-страницы;
• Разного рода категории и разделы блога или каталога;
• Товары и их категории;
• XML-документы, например, sitemap.xml для поисковых роботов;
• Текстовые документы, к примеру, robots.txt правильно сделать ресурсом, а не просто залить файлом;
• Json-страницы, которые лично я использую для того же аякс;
• Создать собственный формат текстового файла.
Постановка проблемы
Вот такое объединение множества различных «сущностей» сайта в объекте одной модели Resources и вызвало мой интерес. Разум философа зашевелился и начал выдавать множество предположений и вопросов.
Во-первых, я обратил внимание на пользователей, потому что они сделаны совершенно отдельно от ресурсов. Как бы на первый взгляд это логично, но с другой стороны, если начали такую пляску с объединением кучи всего, почему бы не сделать все до конца. Да-да, максимализм в деле. Тем более, что сделать пользователей как один из видов ресурсов не представляет большой проблемы. В случае с modx это по большей части реализуется с помощью плейсхолдеров, позволяющих расширить количество атрибутов ресурса, и «контекстов», дающих возможность выделять часть ресурсов по их назначению. Реализация же чего-то подобного на фреймворке (я имею ввиду php-фреймворки) или голой связке скриптов и реляционной базы данных совсем дело не сложное.
Во-вторых, совершенно отдельными моделями реализуются шаблоны и вся система представления и настройки сайта. Почему бы их тоже не объединить в одну модель, хотя бы чисто ради эксперимента. Чувствую летящие в меня помидоры.
От частного к общему
Обобщение – это абстракция, которая позволяет обобщенно представлять себе некоторый класс индивидуальных объектов как единый именованный объект.
Джон М. Смит, Диана К. Смит
По сути, это продолжение работы натурфилософов, только перенесенное в плоскость хранения данных: «Что есть единое» и стоит ли идти путем обобщения при проектировании базы данных? Под обобщением, или переходом от частного к общему, я подразумеваю как раз то слияние нескольких моделей на уровне MVC проекта и соответственно таблиц на уровне базы данных, которое и заметил в modx. Хотя в ситуации с БД все же объединяются не таблицы, а именно ключевые атрибуты (т.н. первичный ключ), что приводит к объединению и таблиц. Но это не означает, что подобную структуру нельзя приводить к нормальной форме.
Давайте разберем чисто гипотетический пример. При проектировании базы данных нам понадобилось хранить и предоставлять доступ к нескольким «сущностям» веб-приложения: администраторы сайта, с разными ролями и правами; клиенты; страницы сайта; тэги; товары; категории. Существует несколько способов построить базу данных. И я говорю не о нормализации БД, которую нужно делать, приводя по хорошему к третьему виду. Я имею ввиду количество или, можно сказать, разнообразие первичных ключей.
Самым естественным и распространенным решением будет делать все «как сказали», то есть для каждой «сущности» свой первичный ключ и набор не ключевых атрибутов, которые при нормализации могут быть выделены в отдельные таблицы (см. Рис.выше). Но при таком решении поднимается несколько вопросов и проблем. И если на вопросы типа «Почему бы администраторов и клиентов не объединить в юзеров с разным уровнем доступа?» можно просто забить. То с проблемами придется разбираться. В плане администраторов нужно решить, как определять их роли и права доступа. Как вариант это создание еще одной «сущности» или даже двух отдельных для прав и для ролей. К тому же появляется важный атрибут определения роли, который и будет решаться этими «сущностями», либо, если они не созданы на уровне БД и определяются в php (кто пишет сайты и приложения на другом языке представьте, что я его тут упомянул, а не php), тогда этот атрибут должен создаваться отдельным полем.
Есть другой вариант решения, который заключается как раз в повышении уровня обобщения базы данных. Можно объединить всех пользователей в один ключевой атрибут, таким образом, получится, что и все администраторы, и все клиенты это пользователи. Но нам нужно их как то отличать, для этого придется вводить не ключевой атрибут ролей, который, в общем-то, у нас был и при первом способе, но не распространялся на клиентов. Таким же образом мы можем объединить страницы сайта, категории, товары и тэги в объект «ресурсы». И тут нам тоже понадобится дополнительный не ключевой атрибут, позволяющий определить какую «сущность» представляет собой тот или иной ресурс. И опять это все можно привести к нормальному виду.
Из таких рассуждений рождается желание понять, как же высоко может подняться уровень обобщения данных. Вполне можно предположить, что пользователи это всего на всего один из видов ресурсов. Если вспомнить опыт modx, который и привел меня к таким размышлениям, то в базу кроме описанных выше «сущностей» нужно добавить роли пользователей, права доступа, шаблоны и некоторые другие, так сказать, сопутствующие данные, типа настроек системы. И даже их можно все объединить в общий уровень обобщения – «объекты». В него отлично вписываются и «ресурсы». Теперь нам просто нужно у каждого элемента уровня объекта иметь атрибут, определяющий к какой «сущности» он относится.
Вот что же мы можем видеть при продвижении вверх по уровням обобщения. Во-первых, для реализации нужен, как теперь оказывается, тоже ключевой атрибут, определяющий положение «сущности» при более низких уровнях – «атрибут обобщения». Он должен отражать значение при самом низком уровне, который мог бы быть. К примеру, у одного из администраторов сайта он может иметь значение «контент менеджер», у других это будет «программист» и тд. Во-вторых, поднимаясь вверх мы в конце приходим к выводу, что все данные в базе делятся на объекты и атрибуты. По сути объекты это такие же поля таблиц, но ключевые и отражающие значение атрибута обобщения.
В-третьих, все уровни обобщения, кроме возможно самого верхнего, позволяют приводить базу к нормальному виду, хотя и могут казаться просто безумнейшим решением. Более того они таковыми и могут оказаться. Давайте представим, что у нас по тысяче страниц, тэгов и клиентов, администраторов и настроек пусть всех в сумме тоже тысяча. У нас получается что при уровне объекта все они будут храниться в одной таблице, даже если мы сделали нормализацию и вынесли атрибуты в другие таблицы. А если объектов в десятки раз больше?
Минимальное обобщение
Мы определились, конечно, от части, с повышением уровня. И хотя это имеет свои плюсы, как то высокий уровень абстракции, даже заоблачный, но минусов все же больше. На мой взгляд их слишком много, особенно если вы делаете highload. Предлагаю посмотреть как низко мы можем опустить уровень обобщения и какие плюсы и минусы это может нести в сравнении с «обычным» уровнем. На самом деле, определить на сколько низкий уровень обобщения возможен получится только с конкретной задачей и результат будет определенно только для нее.
Давайте посмотрим что мы можем сделать с нашим примером. Клиентов, конечно же, мы не будем приписывать к пользователям. Далее раздробим администраторов на нужные нам роли, тем самым избавившись от них, и оставив только права, как атрибуты для каждого из них. Думаю это будет как то так: контент менеджеры, seo админы (скорее всего он будет один), программисты. Так же разделим ресурсы на отдельные части, чем избавимся от необходимости указывать какой «сущностью» является каждый из них. Как мы видим, атрибут обобщения теперь не нужен, получается, что сами данные выполняют его роль. А это позволяет избавится не только от атрибута, но и таблицы и возможно не одной, учитывая что количество атрибутов у ресурсов и пользователей может быть не мало.
Разбивая всех и вся на части мы получаем большее количество таблиц. Теперь пользователи занимают не одну таблицу, кроме всяких там таблиц с дополнительными атрибутами, а четыре в нашем примере. Тоже происходит и с ресурсами, которые были одной таблицей. И с одной стороны количество таблиц увеличивается, но с другой стоит отметить, что мы тут не учитываем как изменится база после ее нормализации. А так же заметим еще два положительных эффекта, особенно приятных при разработке нагруженных приложений. Количество строк в каждой из таблиц становится меньше, да именно тут наблюдается прямая зависимость между уровнем обобщения и загруженностью таблиц. А вот при нормализации такой зависимости нет, более того может быть обратная. И еще один плюс, конечно если им правильно воспользоваться, конкретная цель использования каждой таблицы. Не возникает двусмысленности как при высоких уровнях обобщения базы данных. И хотя большее количество таблиц, на первый взгляд, усложняют проект, при правильном именовании таблиц, сопровождении моделей (если они используются) пояснениями в комментариях – это может служить большей прозрачности работы с базой данных.
С другой стороны, уровень абстракции реализации базы данных падает и это может послужить плохую службу. Так к примеру, если появляется новый тип администраторов, то при высоком уровне нам достаточно внести одно дополнительное значение в атрибут обобщения. Далее можно создавать новых пользователей с присваиванием им этого значения. С минимальной абстракцией обобщения такая красота не прокатит, придется создавать новую основную таблицу для этого типа администраторов, а так же различные дополнительные, либо делать связь с существующими. И встает вопрос «Что если добавится не новый тип пользователя, а новый уровень вниз?», например, программисты вдруг разделятся на бекэнд и фронтэнд.
Источник


