- Информационная модель: описание, структура, виды, типы информационных моделей, разработка, создание, использование информационной модели
- Что называют информационной моделью? Описание и структура
- Общая классификация
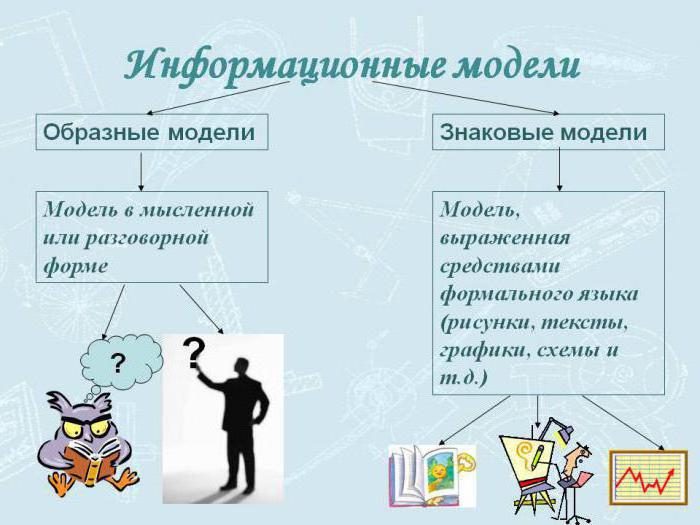
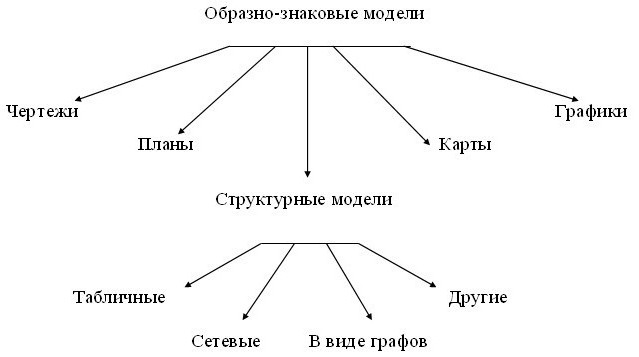
- Виды информационных моделей
- Типы информационных моделей
- Что необходимо для их создания?
- Где применяются информационные модели?
- Пример создания
- Особенности
- Изучение аспектов информационного моделирования
- Заключение
- REST, что же ты такое? Понятное введение в технологию для ИТ-аналитиков
- Терминология
- Что такое REST?
- Принципы REST
- Принцип 1. Клиент-серверная архитектура
- Принцип 2. Stateless
- Принцип 3. Кэширование
- Принцип 4. Единообразие интерфейса. HATEOAS
- Принцип 5. Layered system (слоистая архитектура)
- Принцип 6. Code on done (код по требованию)
- Насколько же сходятся идеи, которые вложил Рэй Филдинг в концепцию REST, с восприятием REST аналитиками?
- Модель зрелости REST-сервисов
- Уровень 0
- Уровень 1
- Уровень 2
- Уровень 3
- Выводы, которые мы можем сделать из модели зрелости
- Подведём итоги
Информационная модель: описание, структура, виды, типы информационных моделей, разработка, создание, использование информационной модели
По мере развития человечества происходит структуризация и оптимизация наличных у нас данных и возможностей их использования. При этом ключевой является информационная модель. На сегодняшний день она является существенно недооценённым инструментов планирования. Чтобы сломать эту тенденцию, необходимо рассказывать аудитории о её возможностях, чем и займётся автор этой статьи.
Что называют информационной моделью? Описание и структура
 Так называют модель объекта. Она представлена в виде информации, что описывает существенные для конкретного случая параметры и переменные, связи между ними, а также входы и выходы для данных, при подаче на которые можно влиять на получаемый результат. Их нельзя увидеть или потрогать. В целом они не имеют материального воплощения, поскольку строятся на использовании одной информации. Сюда относятся данные, что характеризуют состояния объекта, существенные свойства, процессы и явления, а также связь с внешней средой. Это процесс называется описанием информационной модели. Это самый первый шаг проработки. Полноценной информационной моделью является обычно сложная разработка, которая может иметь много структур, что в рамках статьи сведены в три основных типа:
Так называют модель объекта. Она представлена в виде информации, что описывает существенные для конкретного случая параметры и переменные, связи между ними, а также входы и выходы для данных, при подаче на которые можно влиять на получаемый результат. Их нельзя увидеть или потрогать. В целом они не имеют материального воплощения, поскольку строятся на использовании одной информации. Сюда относятся данные, что характеризуют состояния объекта, существенные свойства, процессы и явления, а также связь с внешней средой. Это процесс называется описанием информационной модели. Это самый первый шаг проработки. Полноценной информационной моделью является обычно сложная разработка, которая может иметь много структур, что в рамках статьи сведены в три основных типа:
- Описательная. Сюда относятся модели, которые создаются на естественных языках. Они могут иметь любую произвольную структуру, которая удовлетворит составляющего их человека.
- Формальная. Сюда относят модели, которые создаются на формальных языках (научных, профессиональных или специализированных). В качестве примеров можно привести такое: все виды таблиц, формул, граф, карт, схемы и прочих подобных структурных формаций.
- Хроматические. Сюда относят модели, которые были созданы с применением естественного языка семантики цветовых концептов, а также их онтологических предикатов. Под последними понимают возможность распознавания значений цветовых канонов и смыслов. В качестве примера хроматических моделей можно навести те, что были построены с использованием соответствующей теоретической базы и методологии.
Как видим, основной составляющей являются данные, их структура и процедура обработки. Развивая мысль, можно дополнить, что информационная модель является схемой, в которой описана суть определённого объекта, а также все необходимые для его исследования процедуры. Для более полного описания характеристик используют переменные. Они замещают атрибут цели, которая прорабатывается. И здесь имеет значительную важность структура информационной модели.
Давайте приведём пример. Описание веника и инструкция по его использованию является информационной моделью для уборщика. Но это не всё. Описание и технологический процесс изготовления веника, изложений в соответствующей документации, является информационной моделью и алгоритмом, по которому его делает производитель. Как видите, отражаются наиболее важные свойства объекта. В действительности, конечно, информационная модель – это лишь приближенное описание. В результате можно сказать, что эти данные, с помощью которых осуществляется познание реальности, являются относительно истинными.
Общая классификация
 Какие информационные модели существуют? Классификация сформирована на основе самого определения:
Какие информационные модели существуют? Классификация сформирована на основе самого определения:
- Зависимо от количества значений переменных они делятся на динамические и статистические.
- По способу описания бывают знаковыми, натурными, формализованными.
- Зависимо от особенностей конструирования переменных делятся на графовые, графические, идеографические, текстовые, алгоритмические, табличные.
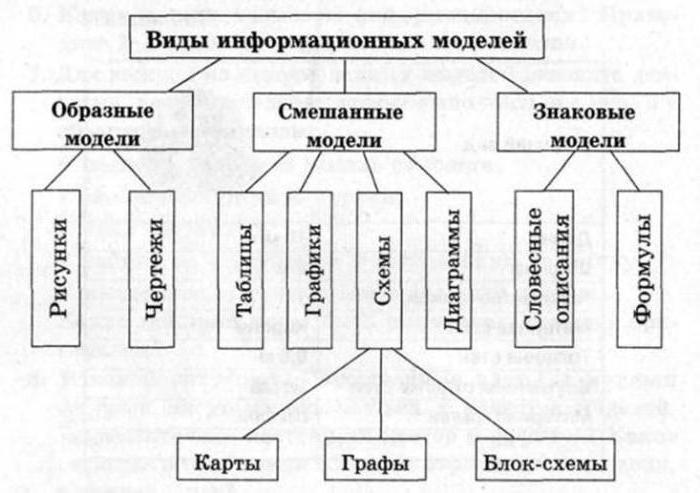
Виды информационных моделей
 Исследованию поддаётся как физический, так и идеальный объект анализа. Это приводит к тому, что существование одинаковых информационных моделей, к которым можно подойти с тем же самых набором инструментариев, нет. Поэтому приходится использовать отдельные подходы и что-то особенное, что позволит изучить или исследовать предметную область. На основании таких суждений принято выделять три виды информационных моделей:
Исследованию поддаётся как физический, так и идеальный объект анализа. Это приводит к тому, что существование одинаковых информационных моделей, к которым можно подойти с тем же самых набором инструментариев, нет. Поэтому приходится использовать отдельные подходы и что-то особенное, что позволит изучить или исследовать предметную область. На основании таких суждений принято выделять три виды информационных моделей:
- Математические. Благодаря им изучают явления и процессы, что являются представленными в виде наиболее общих математических закономерностей или абстрактных объектов, которых достаточно, чтобы выразить законы природы или внутренние свойства наблюдаемого. Также применяются для подтверждения правила логических рассуждений.
- Компьютерные. Используется для описания совокупности переменных, что представлены абстрактными типами данных и поданы в соответствии с выдвигаемыми требованиями среды обработки ЭОМ.
- Материальные. Так называют предметное отражение объекта, сохраняющее геометрические и физические свойства (глобус, игрушки, манекены). Также к материальным моделям относят химические опыты.
Типы информационных моделей
Поскольку они являются совокупностью информации, то часто характеризуют состояние и свойства объекта, явления, процесса и их взаимодействие с окружающим их миром. Зависимо от того, как они представлены и выражены, выделяют два типы информационных моделей:
- Вербальные. Они создаются как результат умственной деятельности человека и представляются в словесной форме или при помощи жестикуляции.
- Знаковые. Для их выражения используются рисунки, схемы, графики, формулы.
Что необходимо для их создания?
 Информация, причём как можно более точная. Чем больше предоставленные данные отвечают реальным показателем, тем эффективней применяется модель на практике. Чтобы разработать модель, сначала проводится сбор всей возможной информации. Она отсеивается и остаётся та, что предоставляет наибольшую ценность для исследователя. Проводится анализ предоставляющей интерес информации, на основании которого она структурируется. И зависимо от целей исследователь из отдельных блоков данных строит необходимую модель. Потом проводится поиск ошибок и ликвидация противоречий. Когда этот шаг закончен, то разработка информационной модели тоже считается завершённой.
Информация, причём как можно более точная. Чем больше предоставленные данные отвечают реальным показателем, тем эффективней применяется модель на практике. Чтобы разработать модель, сначала проводится сбор всей возможной информации. Она отсеивается и остаётся та, что предоставляет наибольшую ценность для исследователя. Проводится анализ предоставляющей интерес информации, на основании которого она структурируется. И зависимо от целей исследователь из отдельных блоков данных строит необходимую модель. Потом проводится поиск ошибок и ликвидация противоречий. Когда этот шаг закончен, то разработка информационной модели тоже считается завершённой.
Где применяются информационные модели?
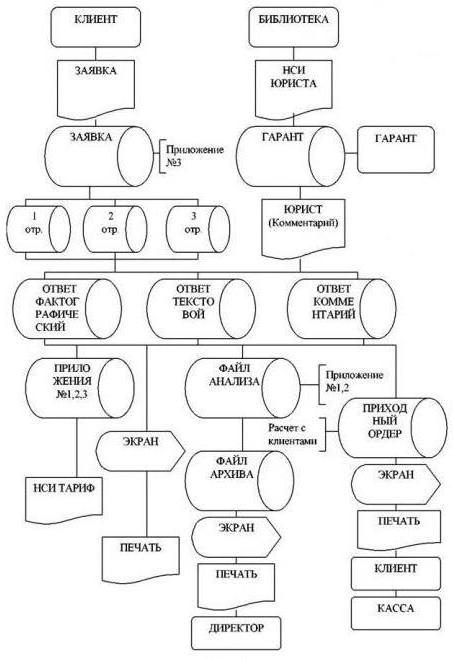 Везде. Только такое обозначение не всегда применяется на практике из-за его излишней научности. Инструкции для компьютеров, телевизоров, телефонов, использованных бутылей воды, автомобильных аккумуляторов – вот лишь отдельные примеры. Информационной моделью является и технология производства комбайнов, тракторов, самолётов, грузовиков, прицепов, строений. Как видите, для неё есть применение и в быту, и в промышленности. Но сам термин «информационная модель» больше применяется в последней сфере из-за того, что здесь протекают более сложные процессы с участием большого количества людей.
Везде. Только такое обозначение не всегда применяется на практике из-за его излишней научности. Инструкции для компьютеров, телевизоров, телефонов, использованных бутылей воды, автомобильных аккумуляторов – вот лишь отдельные примеры. Информационной моделью является и технология производства комбайнов, тракторов, самолётов, грузовиков, прицепов, строений. Как видите, для неё есть применение и в быту, и в промышленности. Но сам термин «информационная модель» больше применяется в последней сфере из-за того, что здесь протекают более сложные процессы с участием большого количества людей.
Пример создания
Давайте попробуем детально проанализировать, что такое информационная модель. Это не так сложно, как может показаться. В качестве примера возьмём клавиатуру. Можно определить два направления относительно пользователя: описание и вопросы настройки. Во-первых, производительно пишет в аннотации, какой это хороший продукт, что он может, как с ним удобно работать. Анализирует передовые технологии, применённые при её создании, экологические преимущества и прочие подобные вещи. Главное – понравиться. Но лгать всё же не надо, поскольку это будет иметь нежелательные последствия.
Во-вторых, прорабатываются вопросы настройки. Можно ответить на них с помощью картинок на листке-вкладыше, где будет изображено, куда вставить разъём клавиатуры в компьютер. Также может прилагаться небольшой ремонтный комплект, инструкция по его использованию, особенности построение устройства, как его следует разбирать в случае возникновения определённых проблем – и ряд других вопросов, которые можно только продумать и дать ответ пользователям на них.
Особенности
 Чем больше данных, тем описание информационной модели будет сложнее. Это две стороны медали: следует выбирать между точностью и функциональностью. Чтобы не перегибать палку или избежать слабой проработки вопроса следует заранее очертить задачи для проработки и глубину их разбора. Следует позаботиться обо всех имеющихся моментах, поскольку любая проблема, допущенная на этом этапе, в будущем только добавит работы и необходимость затраты денежных средств на устранение конфликта.
Чем больше данных, тем описание информационной модели будет сложнее. Это две стороны медали: следует выбирать между точностью и функциональностью. Чтобы не перегибать палку или избежать слабой проработки вопроса следует заранее очертить задачи для проработки и глубину их разбора. Следует позаботиться обо всех имеющихся моментах, поскольку любая проблема, допущенная на этом этапе, в будущем только добавит работы и необходимость затраты денежных средств на устранение конфликта.
Изучение аспектов информационного моделирования
 С научной точки зрения этим вопросом занимается кибернетика. Поэтому, если у вас есть желание углубить свои познания в этой области, запаситесь несколькими недавно вышедшими книгами и внимательно изучите их. Хотя можно и по-другому осведомиться, что такое простейшие информационные модели. Информатика может дать необходимый базис, но для получения всей полноты знаний нужна именно кибернетика. В её рамках можно будет ознакомиться не только с детализированными принципами моделирования, но и узнать про существующие разработки, а также возможности их применения.
С научной точки зрения этим вопросом занимается кибернетика. Поэтому, если у вас есть желание углубить свои познания в этой области, запаситесь несколькими недавно вышедшими книгами и внимательно изучите их. Хотя можно и по-другому осведомиться, что такое простейшие информационные модели. Информатика может дать необходимый базис, но для получения всей полноты знаний нужна именно кибернетика. В её рамках можно будет ознакомиться не только с детализированными принципами моделирования, но и узнать про существующие разработки, а также возможности их применения.
Заключение
 Информационная модель – это важный и полезный инструмент, если правильно его использоваться. При создании сложных систем (например, программного обеспечения) он позволяет проработать основные технические вопросы и устранить возможные не состыковки. В рамках статьи были размещены знания про то, какие информационные модели есть, как они создаются и другая полезная информация, что пригодится на практике.
Информационная модель – это важный и полезный инструмент, если правильно его использоваться. При создании сложных систем (например, программного обеспечения) он позволяет проработать основные технические вопросы и устранить возможные не состыковки. В рамках статьи были размещены знания про то, какие информационные модели есть, как они создаются и другая полезная информация, что пригодится на практике.
Источник
REST, что же ты такое? Понятное введение в технологию для ИТ-аналитиков
Мы подготовили статью Андрея Буракова на основе его вебинара на нашем YouTube-канале:
Проектирование и работа с REST-сервисами стали повседневными задачами для многих аналитиков. Однако мы часто встречаемся на работе с различными или даже противоречащими друг другу трактовками таких понятий, как REST, RESTful-сервис, RESTAPI.
Сегодня мы разберём, какие принципы вложил в парадигму REST её автор и как они могут помочь нам при проектировании систем.
Выясним, почему существует терминологическая путаница вокруг REST и как нам научиться лучше понимать коллег.
Поговорим о том, как связаны HTTP и REST. А также почему REST противопоставляют SOAP.
Терминология
Формат представления данных
Давайте представим, что я живу в девятнадцатом веке и хочу отправить письмо своему клиенту, который заинтересован в покраске своего автомобиля. Разумеется, я должен написать в письме про то, какие цвета для покраски автомобиля имеются в автосалоне.
Перед тем, как отправить письмо, я беру лист бумаги и пишу клиенту, что в автосалоне сейчас доступны цвета: синий, зелёный, красный, белый, чёрный.
Но я мог бы написать это и на английском: blue, green, red, white, black.
Выходит, что одна и та же информация может быть представлена разными способами. И такой способ представления одной и той же информации разными способами будем называть форматом представления данных.
Plain text — это обычный текст, который я использовал при написании письма;
XML — язык разметки информации;
JSON — текстовый формат обмена данными;
Binary — бинарный формат.
Давайте запомним из этой части статьи что XML и JSON — это форматы представления данных.
Протокол передачи данных
Я написал письмо и теперь хочу его отправить. Что мне нужно для этого сделать? Как правило, я кладу письмо в конверт. В нашем случае таким конвертом будет такое понятие, как протокол передачи данных.
Протокол передачи данных — это набор соглашений, которые определяют обмен данными между различными программами. Эти соглашения задают единообразный способ передачи сообщений и обработки ошибок.
 Аналогия протокола передачи данных с письмом в конверте
Аналогия протокола передачи данных с письмом в конверте
Если продолжать рассматривать аналогию с письмом, то стоит обратить, что:
1. конверт имеет структуру;
2. я наклеиваю на конверт марки, указываю определённую информацию: от кого письмо, куда я его отправляю, адрес и т.д.
Транспорт
Получил письмо в конверте, всё здорово! Но нужно его как-то отправить. Как мне его отправить? Я воспользуюсь услугами почты. Что для этого нужно сделать? Прийти на почту, отдать письмо. Затем его кто-то должен доставить, используя некоторый транспорт.
Транспорт — это подмножество сетевых протоколов, с помощью которых мы можем передавать данные по сети.
Такими протоколами могут быть, например: HTTP, AMQP, FTP.
Если продолжать аналогию с письмом, то почтовая служба может отправить это письмо с помощью голубя или, например, с помощью совы. Вроде бы, письмо одно и то же. Конверт (протокол) один и тот же, формат данных один и тот же, но, обратите внимание — транспорт разный.
Чтобы указать, что данные в определенном формате передаются с помощью некоторого транспорта, часто используют запись вида over .
Протокол HTTP
HyperText Transfer Protocol (HTTP) — это протокол передачи данных. Изначально для передачи данных в виде гипертекстовых документов в формате HTML, сегодня — для передачи произвольных данных.
Этот протокол имеет две особенности, которые должны учитывать все, кто работает с этим протоколом: ресурсы и HTTP-глаголы.
Ресурсы
Чтобы разобраться с понятием ресурса, давайте представим, что у нас имеется некоторая ссылка: http://webinar.ru/schedule/speech.
Это как раз и есть тот самый URL, который мы используем поверх HTTP. Рассмотрим, из чего состоит эта ссылка:
А вот как нам работать с этими объектами, нам говорят HTTP-глаголы (методы).
HTTP-глаголы
HTTP-глаголы — это элемент протокола HTTP, который используется в каждом запросе, чтобы указать, какое действие нужно выполнить над данным ресурсом.
GET/schedule/speech/id413 — получить информацию об объекте
Здесь мы видим некоторый объект (ресурс) с конкретным идентификатором с номером 413. Я могу использовать HTTP-глагол GET для, того чтобы получить информацию о выступлении 413.
Я могу воспользоваться каким-либо другим HTTP-глаголом, если мне необходимо выполнить какие-либо другие действия.
PUT/schedule/speech/id413 — создать или перезаписать объект
Или удалить объект:
Главное здесь то, что мы рассматриваем некоторые объекты (ресурсы) и совершаем над ними некоторые действия, которые определены в протоколе списком HTTP-методов: GET, PUT, POST, DELETE и т.д.
Что такое REST?
Какое же определение в понятие REST заложил его основатель Рой Филдинг?
Representational State Transfer — это архитектурный стиль взаимодействия компонентов распределённого приложения в сети. Архитектурный стиль – это набор согласованных ограничений и принципов проектирования, позволяющий добиться определённых свойств системы.
Но зачем нам REST? Зачем нам этот стиль? Что нам даст применение принципов REST?
Если мы обратимся опять же к первоисточнику — к работе Филдинга, то мы выясним, что назначение REST в том, чтобы придать проектируемой системе такие свойства как:
Гибкость к изменениям,
Это наиболее ценные свойства, с которыми встречается, например, аналитик при проектировании систем. В действительности их намного больше. Если внимательно посмотреть на эти свойства, то мы увидим ни что иное, как нефункциональные требования к системе, которых мы на своих проектах стремимся достичь.
Принципы REST
Каким образом REST может помочь нам достичь этих свойств и реализовать эти нефункциональные требования?
Чтобы это понять, давайте рассмотри 6 принципов REST — ограничений, которые и помогают нам добиться этих нефункциональных требований.
6 принципов REST:
Далее мы рассмотрим эти шесть принципов поподробнее.
Принцип 1. Клиент-серверная архитектура
Сама концепция клиент-серверной архитектуры заключается в разделении некоторых зон ответственности: в разделении функций клиента и сервера. Что это означает?
Например, мы разделяем нашу систему так, что клиент (допустим, это мобильное приложение) реализует только функциональное взаимодействие с сервером. При этом сервер реализует в себе логику хранения данных, сложные взаимодействия со смежными системами и т.д.
Что мы этим добиваемся и как могло бы быть иначе? Давайте представим, что клиент и сервер у нас объединены. Тогда, если мы говорим о мобильном приложении, каждое мобильное приложение каждого клиента должно было бы быть абсолютно самодостаточной единицей. И тогда, поскольку у нас единого сервера нет для получения/отправки информации, у нас получилась бы какая-то сеть единообразных компонентов – например, мобильные приложения общались бы друг с другом – такая распределённая сеть равноценных узлов.
Такие системы в реальной жизни есть и можно найти их примеры. Например, в блокчейне. Тем не менее, в случае с REST мы говорим о том, что разделяем ответственность. Например, отображение информации, её обработку и хранение.
Клиент-серверная архитектура
Также сервер может иметь базу данных (см. рисунок ниже). В данном случае надо понимать, что пара «сервер и БД» тоже будет парой «клиент-сервер». Только в данном случае сервером будет БД, а сам сервер — клиентом.
Трёхзвенная архитектура
Что дает клиент-серверная архитектура и зачем она нужна?
Во-первых, клиент-серверная архитектура дает нам определённую масштабируемость: есть сервер, есть единая точка обработки запросов. При необходимости выдерживать большую нагрузку мы можем поставить несколько серверов. Также к нему можно подключать достаточно большое количество клиентов (сколько сможет выдержать). Таким образом, клиент-серверная архитектура позволяет добиться масштабируемости.
Во-вторых, REST даёт определённую простоту поддержки. Если мы хотим изменить логику обработки информации на сервере, то выполним эти изменения на сервере. В данном случае мы можем и не менять каждого клиента, как если бы они были абсолютно равноценной сетью.
Конечно, есть и минусы. В случае с клиент-серверной архитектурой мы понимаем, что у нас есть единая точка отказа в виде сервера. Если отказал сервер и у нас нет дополнительных инстансов, то для нас это будет означать неработоспособность системы.
Также потенциально может увеличиться нагрузка, поскольку часть логики мы вынесли с клиента на сервер. Клиент будет совершать меньше каких-либо действий самостоятельно, соответственно, у нас возрастёт количество запросов между клиентом и сервером.
Принцип 2. Stateless
Принцип заключается в том, что сервер не должен хранить у себя информацию о сессии с клиентом. Он должен в каждом запросе получать всю информацию для обработки.
Пример реализации принципа Stateless. Запрос погоды на 20.06 в Москве
Представим, что у нас есть некоторый сервис прогноза погоды, в котором уже реализована клиент-серверная архитектура, и мы хотим получить сообщение о прогнозе погоды на завтра.
Что мы делаем в случае, если мы работаем с Stateless? Мы отправляем запрос «Какая погода?», отправляем место, где хотим погоду узнать, и дату. Соответственно, прогноз погоды отвечает нам — «Будет жарко».
Если я захочу узнать, какая будет погода через день, то опять укажу место, где хочу узнать погоду, укажу другую дату. Сервер получит этот запрос, обработает и сообщит мне, что там уже будет очень жарко.
Пример реализации принципа Stateless. Запрос погоды на 21.06 в Москве
Рассмотрим ситуацию: что было бы, если бы у нас не было Stateless? В таком случае у нас бы был Stateful. В этом случае сервер хранит информацию о предыдущих обращениях клиента, хранит информацию о сессии, какую-то часть контекста взаимодействия с клиентом. А затем может использовать эту информацию при обработке следующих запросов.
Приведём пример на рисунке:
Пример реализации принципа Stateful
Я всё так же хочу узнать, какая погода будет завтра: отправляю запрос, сервер его обрабатывает, формирует ответ и, помимо того, что он возвращает ответ клиентам, он еще сохраняет какую-то информацию (часть или всю) о том, какой запрос он получил. В случае, если я захочу узнать, какая погода будет через день, я могу сделать такой вызов: «А завтра?». Не сообщая ничего о месте и о дате.
В этом случае у сервера хранится некоторый контекст. Он понимает, что я у него спрашиваю про 21-е число и могу дать ответ на основе информации, хранимой у него в БД или в кэше. Один из примеров, где можно встретить подход Stateful в жизни — это работа с FTP-сервером.
Вернёмся к Statless-подходу. Почему в REST-архитектуре мы должны использовать именно Statless-подход?
Какие он даёт плюсы?
Уменьшение времени обработки запроса,
Возможность использовать кэширование.
В первую очередь, это масштабирование сервера. Если каждый запрос содержит в себе абсолютно весь контекст, необходимый для обработки, то можно, например, клонировать сервер-обработчик: вместо одного поставить десять таких. Мне будет абсолютно неважно, в какой из этих клонов придёт запрос. Если бы они хранили состояние, то либо должны были синхронизироваться, либо мне нужно было бы умело направлять запрос в нужное место.
Помимо этого, появляется простота поддержки. Каждый раз я вижу в логах, какое сообщение приходило от клиента, какой ответ он получал. Мне не нужно дополнительно узнавать о том, какое состояние хранил сервер.
Также подход Stateless позволяет использовать кэширование.
Какие проблемы может создать Stateless-подход?
Усложнение логики клиента (именно на стороне клиента нам нужно хранить всю информацию о состоянии, о допустимых действиях, о недопустимых действиях и подобных вещах).
Увеличение нагрузки на сеть (каждый раз мы передаём всю информацию, весь контекст. Таким образом, больше информации гоняем по сети).
Принцип 3. Кэширование
В оригинале этот принцип говорит нам о том, что каждый ответ сервера должен иметь пометку, можно ли его кэшировать.
Что такое кэширование?
Представим, что у нас всё так же есть сервис по прогнозу погоды, есть клиент, с которым взаимодействуют. Сам по себе этот сервис погоду не определяет. Погоду определяет метеостанция, с которой он связывается с помощью специальных удалённых вызовов. Что происходит, когда мы используем кэширование?
Например, клиент обратился к серверу с запросом «Хочу узнать погоду». Что делает сервер?
Если мы его только запустили и используем кэширование или если мы не используем кэширование вообще — сервер обратится к метеостанции, а она вернёт ему ответ. Перед тем, как сервер ответит клиенту, он должен сохранить эту информацию в кэше. И только потом вернуть ответ. Для чего?
Когда клиент в следующий раз отправит ровно такой же запрос, сервер сможет не обращаться к метеостанции. Он сможет извлечь прогноз из кэша и вернуть ответ клиенту.
Пример реализации архитектуры с использованием кэширования
Чего мы добились? Мы убрали одну часть взаимодействия между сервером и метеостанцией. Зачем нам это нужно? Это нужно и полезно, если у сервера часто запрашивают одинаковую информацию. Например, кэширование активно используется на новостных сайтах или в соцсетях (на веб-ресурсах, к которым происходит много обращений).
Какие у кэширования плюсы?
Уменьшение количества сетевых взаимодействий.
Уменьшение нагрузки на системы (не грузим их дополнительными запросами).
В каких-то случаях одинаковых обращений будет не так много. Тогда кэширование использовать нет смысла.
При этом важно понимать, что кэширование — это совсем не простая штука. Она бывает достаточно сложна и нетривиальна в реализации.
Также мы должны учитывать, что если отдаём какие-то данные, которые сохранили раньше, то важно помнить, что эти данные могли уже устареть.
В каких-то случаях это может быть приемлемо, но в каких-то случаях — абсолютно недопустимо. Соответственно, стоит ли использовать кэширование — всегда нужно обдумывать на конкретном примере.
Принцип 4. Единообразие интерфейса. HATEOAS
Hypermedia as the Engine of Application State (HATEOAS) — одно из ограничений REST, согласно которому сервер возвращает не только ресурс, но и его связи с другими ресурсами и действия, которые можно с ним совершить.
Рассмотрим пример. Возьмём HTTP-запрос, в котором я хочу получить определенный ресурс:
Пример запроса ресурса
Здесь мы используем HTTP-глагол GET, то есть хотим получить ресурс. Обращаемся к некоторому счёту с номером 12345.
Если бы мы не использовали подход HATEOAS, то получили бы примерно такой XML-ответ:
Пример ответа без использования принципа HATEOAS
Здесь указан номер счёта, баланс и валюта.
Что же предлагает HATEOAS? Если бы мы с учётом этого ограничения выполняли бы этот запрос, то в ответе получим не только информацию об этом объекте, но и все те действия, которые мы можем с ним совершить. И, если бы у него были бы какие-то важные связанные объекты, мы получили бы ещё и ссылки на них.
Пример ответа с использованием принципа HATEOAS
Получая такие ответы, клиент самостоятельно понимает, какие конкретные действия он может совершать над этим объектом и какую ещё информацию о связанных объектах он может получить. Мы даём клиентскому приложению намного больше информации и свободы действий. Логика клиента становится более гибкой, но при этом и более сложной.
Главный плюс этого подхода — клиент становится очень гибким в плане изменений на сервере с точки зрения изменения допустимых действий, изменения модели данных и т.д.
В качестве обратной стороны медали мы получаем сильное усложнение логики, в первую очередь, клиента. Это может потянуть за собой и усложнение логики на сервере, потому что такие ответы нужно правильно формировать. Фактически ответственность за действия, которые совершает клиент, мы передаём на его же сторону. Мы ослабляем контроль валидности совершаемых операций на стороне сервера.
Принцип 5. Layered system (слоистая архитектура)
В предыдущих схемах мы рассматривали сторону клиента и сторону сервера, но не думали, что между ними могут быть посредники.
В реальной жизни между ними могут быть, к примеру, proxy-сервера, роутеры, балансировщики — все, что угодно. И то, по какому пути запрос проходит от клиента до сервера, мы часто не можем знать.
Концепция слоистой архитектуры заключается в том, что ни клиент, ни сервер не должны знать о том, как происходит цепочка вызовов дальше своих прямых соседей.
Модель слоистой архитектуры
Знания балансировщика в этой схеме об участниках конкретно этой цепочки вызовов должны заканчиваться proxy-сервером слева и сервером справа. О клиенте он уже ничего не знает.
Если изменяется поведение proxy-сервера (балансировщика, роутера или чего-то ещё), это не должно повлечь изменения для клиентского приложения или для сервера. Помещая их в эту цепочку вызовов, мы не должны замечать никакой разницы. Это позволяет нам изменять общую архитектуру без доработок на стороне клиента или сервера.
Увеличение нагрузки на сеть (больше участников и больше вызовов, чем если бы мы шли один раз от клиента до сервера напрямую).
Увеличение времени получения ответа (из-за появления дополнительных участников).
Принцип 6. Code on done (код по требованию)
Идея передачи некоторого исполняемого кода (по сути какой-то программы) от сервера клиенту.
Модель архитектуры, реализующей принцип «Код по запросу»
Представьте, что клиент — это, например, обычный браузер. Клиент отправляет некоторый запрос и ждёт ответа — страницу с определённым интерактивом (например, должен появляться фейерверк в том месте, где пользователь кликает кнопкой мышки). Это всё может быть реализовано на стороне клиента.
Либо клиент, запрашивая данную страницу приветствия, получит в ответ от сервера не просто HTML-код для отображения, а ещё программу, которую он сам и исполнит. Получается, что сервер передаёт исходный код клиенту, а тот его выполняет.
Что мы за счёт этого получаем? Отчасти, это схоже с принципом HATEOAS. Мы позволяем клиенту стать гибче. Если мы захотим изменить цвет фейерверка, то нам не нужно вносить изменений на клиенте — мы можем сделать это на сервере, а затем передавать клиенту. Пример такого языка — javascript.
Насколько же сходятся идеи, которые вложил Рэй Филдинг в концепцию REST, с восприятием REST аналитиками?
Давайте рассмотрим наиболее частые заблуждения, которые вы можете встретить относительно концепции REST.
1. Ограничения REST опциональны (необязательны)
С точки зрения создателя этой концепции существует ровно одно необязательное ограничение — код по требованию. Все остальные ограничения должны выполняться. Если одно из них не выполняется — это уже не REST-подход.
2. REST — протокол передачи данных
REST — это не протокол передачи данных. Он не определяет правила о том, как мы должны передавать запросы, какая у них должна быть структура, что мы должны возвращать в ошибках. Единственное, что косвенно можно было бы приписать — это указание на то, что каждый ответ сервера должен содержать информацию о том, можно ли его кэшировать.
Но, в целом, REST — это концепция, парадигма, но не протокол. В отличие от HTTP, который действительно является протоколом.
3. REST — это всегда HTTP
С одной стороны, ни один из архитектурных принципов REST не говорит нам о том, какой транспорт мы должны использовать — HTTP или очереди.
Но при этом в жизни очень часто встречаются люди, для которых REST и HTTP — это аксиома.
Поэтому, если сказать человеку, что REST — это необязательно HTTP, то вас могут посчитать сумасшедшими.
Почему же все считают, что REST — это HTTP? Здесь нужно сделать ремарку, что одним из главных авторов протокола HTTP — это Рэй Филдинг, автор концепции REST. Рэй Филдинг стремился спроектировать HTTP так, чтобы с помощью него концепцию REST было максимально удобно реализовывать.
4. REST — это обязательно JSON
Почему так сложилось? Главная причина в том, что какое-то время назад сервисы вида JSON over HTTP стали противопоставлять SOAP. JSON одновременно стал популярным и стал антагонистом XML, как SOAP подходу. JSON использовался, потому что это не SOAP.
Модель зрелости REST-сервисов
Ричардсон выделил уровни зрелости REST-сервисов. Выделение происходило исходя из подхода, что REST — это, с точки зрения протокола, всё-таки HTTP. Соответственно, он спроектировал модель, по которой можно понять: насколько сервис REST или не REST.
Уровень 0
В первую очередь, он выделил нулевой уровень. К нему относятся любые сервисы, которые в качестве транспорта используют HTTP и какой-то формат представления данных. Например, когда мы говорим про JSON over HTTP – мы говорим про нулевой уровень.
Если более наглядно «пощупать ручками» с точки зрения использования протокола HTTP, то можно представить, что мы выставляем некоторый API. Мы начинаем с того, что объявляем единый путь для отправки команд и всегда используем один и тот же HTTP-глагол для совершения абсолютно любых действий с любыми объектами. Например: создай вебинар, запиши вебинар, удали вебинар и т.д. То есть мы всегда используем один и тот же URL и всегда используем один и тот же HTTP-метод, обычно POST.
Как один из примеров:
Пример 0-го уровня соответствия REST
Уровень 1
Следующий уровень — первый. Мы уже научились использовать разные ресурсы и делаем это не по одному URL. Но при этом всё ещё игнорируем HTTP-глаголы.
Мы просто разделяем явно наши объекты, как некоторые ресурсы. Например: спикер, курс, вебинар. Но, независимо от того, что мы хотим сделать — удалить, создать, редактировать, мы всё равно используем один и тот же HTTP-глагол POST.
Пример 1-го уровня соответствия REST
Уровень 2
Второй уровень — это когда мы начинаем правильно с точки зрения спецификации HTTP-протокола использовать HTTP-глаголы.
Например, если есть спикер, то, чтобы создать спикера и получить информацию о нём, я использую соответствующий глагол: GET, POST. Когда хочу создать или удалить спикера — я использую глаголы: PUT, DELETE.
По сути, второй уровень зрелости — это то, что чаще всего называют REST.
Надо понимать, что, с точки зрения изначальной концепции, если мы дошли до второго уровня зрелости, то это еще не означает, что мы спроектировали REST-систему/ REST-сервис. Но в очень распространённом понимании соответствие 2-ому уровню часто называют RESTfull сервисом.
RESTfull-сервис — это такой сервис, который спроектирован с учётом REST-ограничений. Хотя, в целом, правильнее сервис такого уровня зрелости называть HTTP-сервисом или HTTP-API, нежели REST-API.
Пример 2-го уровня соответствия REST
Уровень 3
Третий уровень зрелости — это уровень, в котором мы начинаем использовать концепцию HATEOAS. Когда мы передаём информацию, ресурсы, мы сообщаем потребителям (клиентам) о том, какие ещё действия необходимо совершить ресурсу, а также связи с другими ресурсами.
Пример 3-го уровня соответствия REST
Выводы, которые мы можем сделать из модели зрелости
Итак, как нам эта модель может помочь понять то, что наши коллеги называют RESTом в каждой отдельно взятой компании? REST у вас или не REST?
Первая распространенная трактовка термина REST — всё, что передаётся в виде JSON поверх HTTP.
Вторая, не менее популярная версия, REST — это сервис второго уровня зрелости, то есть HTTP-API, составленное в соответствии со спецификацией HTTP-протокола. Если мы правильно выделяем ресурсы, правильно используем HTTP-глаголы, а также выполняем некоторые требования HTTP-протокола, то у нас REST.
Что называют RESTом?
Подведём итоги
Во-первых, у каждого свой REST. Мнения о том, что такое REST, часто разнятся. Когда мы работаем с новыми проектами, новыми коллегами или специалистами, очень важно понять, что именно ваш коллега называет RESTом. Это полезно для того, чтобы на одном из этапов проектирования или разработки не оказалось, что мы половину проекта говорили о разных вещах.
Во-вторых, принципы REST мы часто применяем в жизни. Они очень полезны для осмысления. Кэширование, STATELESS и STATEFUL, клиент-серверная модель или код по требованию — это те вещи, которые аналитику полезно знать для понимания.
Третье — это то, что парадигма REST помогает нам выявить и определить важнейшие свойства архитектуры — масштабируемость, производительность и т.д.
1. Способы описания API
2. Инструменты для тестирования API
Источник


