- Дисперсионный анализ ANalysis Of VAriance (ANOVA) просто о сложном
- Условия применения дисперсионного анализа ANOVA
- Статистическая информация для применения однофакторного дисперсионного анализа
- Апостериорные значения
- Пример
- Дисперсионный анализ: соединение теории и практики
- Дисперсионный анализ: основные понятия
- Однофакторный дисперсионный анализ: суть метода, формулы, примеры
- Суть метода, формулы
- Однофакторный дисперсионный анализ: примеры
- Однофакторный дисперсионный анализа в MS Excel
- Двухфакторный дисперсионный анализ без повторений: суть метода, формулы, пример
- Двухфакторный дисперсионный анализ без повторений: пример
- Двухфакторный дисперсионный анализ без повторений в MS Excel
- Двухфакторный дисперсионный анализ с повторениями: суть метода, формулы, пример
- Двухфакторный дисперсионный анализ с повторениями: пример
- Двухфакторный дисперсионный анализ с повторениями в MS Excel
Дисперсионный анализ ANalysis Of VAriance (ANOVA) просто о сложном

Кирилл Сергеевич Мильчаков
В данной статье пойдет речь о сути применения дисперсионного анализа и смысле это процесса. Казалось бы зачем мне нужен дисперсионный анализ (ANOVA) если существует такой прекрасный и понятный статистический критерий, как т-критерий Стьюедента? Однако, здесь стоит внимательно разобраться. Главное ограничение т-критерия перед дисперсионным анализом состоит в том, что первый предназначен для парных сравнений, то есть ситуации, когда у нас есть только две группы и он нуждается в поправках на множественные сравнения, в случае, если у нас более двух групп, во-вторых представим, если у нас 6 групп и мы ищем статистически значимые различия между ними, сколько попарных сравнений в таком случае нужно сделать? Много 🙂
В таком случае гораздо проще использоваться критерий, который предназначен для ситуаций, когда много групп и который нам даст единый ответ на все изучаемые группы — дисперсионный анализ.
Условия применения дисперсионного анализа ANOVA
Перед тем как приступить к применению дисперсионного анализа, который предназначен для минимизации риска неправильной оценки ошибки 1 рода в случае множественных сравнений необходимо убедиться в соблюдении ряда условий:
- Количественный непрерывный тип данных, дискретные данные менее желательны.
- Независимые между собой выборки.
- Нормальное распределение признака в статистических совокупностях, из которых извлечены выборки.
- Равенство (гомогенность) дисперсий изучаемого признака в статистических совокупностях из которых извлечены выборки, проверяется с помощью критерия Levene.
- Независимые наблюдения в каждой из выборок.
Статистическая информация для применения однофакторного дисперсионного анализа
Ho в случае однофакторного дисперсионного анализа (ANOVA) подразумевает, что средние генеральных совокупностей из которых были извлечены выборки равны, другими словами все они относятся к одной генеральной совокупности и различия носят случайный характер. Для проверки теорий в случае дисперсионного анализа используется F-распределение. F-статистика принимает только положительные или нулевые значения.
Процедура дисперсионного анализа состоит в определении соотношения систематической (межгрупповой) дисперсии к случайной (внутригрупповой) дисперсии в измеряемых данных. В качестве показателя изменчивости используется сумма квадратов отклонения значений параметра от среднего: SS (от англ. Sum of Squares). Общая сумма квадратов SSTotal раскладывается на межгрупповую сумму квадратов SSBG[1] и внутригрупповую сумму квадратов SSWG[2]:
В случае если верна Ho, то как внутригрупповая, так и межгрупповая дисперсии служат оценками одной и той же дисперсии и должны быть приблизительно равны.
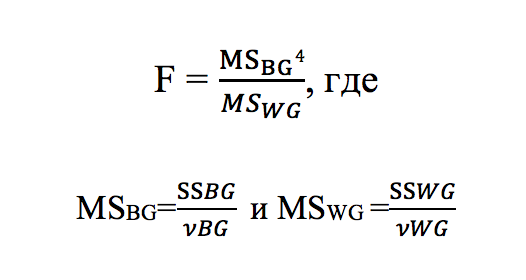
Исходя из этого значение F должно быть близко к 1 в случае, если статистически значимых различий все-таки нет. Критическое значение F определяется уровнем значимости (обычно 0,05 или 0,01) и внутригрупповым и межгрупповым числом степеней свободы (ν). Оно достаточно сложно для вычисления, поэтому чаще используются табличные значения с указанием α, νBG, νWG.
Межгрупповое число степеней свободы:
Внутригрупповое число степеней свободы:
n – количество наблюдений в каждой из групп
Апостериорные значения
Однако, при обнаружении статистически значимых отличий мы не сможем сказать лишь об их наличии, но какие именно группы отличаются друг от друга мы определить не сможем, для этого производят так называемые процедуры апостериорных сравнений. Апостериорные сравнения представляют собой попарные сравнения изучаемых групп для обнаружения различий между ними.
Апостериорные сравнения могут быть проведены с помощью критерия Стьюдента для независимых выборок, что может показаться странным, учитывая сказанное ранее о проблеме множественных сравнений. Однако в отличие от простых попарных сравнений при проведении апостериорных сравнений рассчитываются новые критические уровни значимости для удержания ошибки 1 типа в пределах 5 %.
Наиболее простым и наиболее популярным способом коррекции ошибки 1 типа является поправка Бонферрони (Bonferroni), при которой уровень ошибки 1 типа делится на количество сравнений для получения нового критического уровня значимости. Так, если имеется 3 сравнения, то новый критический уровень должен быть 0,05 / 3 = 0,017. Поправка Бонферрони хорошо контролирует ошибку 1 типа, но является очень консервативной и приводит к повышению вероятности ошибки 2 типа (вероятности принятия решения об отсутствии различий там, где они на самом деле есть). Либеральные критерии, (например критерий Тьюки) в свою очередь, завышают вероятность ошибки 1 типа, то есть вероятность принятия решения о наличии различий там, где их нет.
Таким образом, при выборе статистического критерия для апостериорных сравнений необходимо принимать во внимание, как критерии контролируют ошибки 1 и 2 типов и как они работают при несоблюдении необходимых условий применения дисперсионного анализа.
Если данные не подчиняются нормальному распределению, то при анализе можно использовать два способа: применением различных арифметических преобразований до достижения нормальности распределения и дальше уже применять дисперсионный анализ, или использовать критерий Краскела-Уоллиса (Kruskal-Wallis H-test), иногда его также называют непараметрическим дисперсионным анализом. Как и в большинстве непараметрических методов, работающих с количественными данными, исходный набор данных преобразуется в ранги и обрабатывается уже он. При обнаружении статистически значимых различий между группами стоит дальше проводить апостериорные сравнения с использованием критерия Манна-Уитни.
Пример
В условиях крупной городской клинической больницы было решено провести исследование по оценке влияния возраста на длительность госпитализации после лапароскопической холецистектомии. 9 пациентов были разделены на 3 группы в зависимости от возраста
Длительность госпитализации
после лапароскопической холецистектомии в зависимости от возраста, дни
| Группа №1Младше 45 лет | Группа №245-55 лет | Группа №3Старше 55 лет |
| 3 | 5 | 7 |
| 1 | 3 | 6 |
| 2 | 4 | 5 |
| x̄=2 | x̄=4 | x̄=6 |
Сделайте выводы о влиянии возраста на длительности госпитализации после лапароскопической холецистектомии.
H0 указывает на отсутствие различий между группами, иными словами все группы по возрасту относятся к одной генеральной совокупности и соответственно средние равны друг другу
Альтернативная гипотеза выдвигает предположение, что длительно госпитализации зависит от возраста и средние в этих группах на самом деле не равны
Для этого нам нужно знать общую среднюю по всем выборкам, найдем ее:
SST = 2 = (3-4) 2 +(1-4) 2 +(2-4) 2 +(5-4) 2 +(4-4) 2 +(3-4) 2 +(7-4) 2 +
- Найдем сумму квадратов внутри групп последовательно вычитая из каждого значения в группе групповую среднюю:
SSWG = (3-2) 2 + (1-2) 2 + (2-2) 2 + (5-4) 2 + (3-4) 2 + (4-4) 2 + (7-6) 2 + (6-6) 2 + (5-6) 2 =2+2+2=6
- Найдем внутригрупповую сумму квадратов.
Для этого нам необходимо найти квадрат отклонения каждой из выборочных средних относительно общей вредней:
- Найдем значение критерия Фишера, исходя из средних квадратов отклонений внутри групп и между ними и соответствующих степеней свободы:
νBG = m – 1 = 3-1 = 2
νWG = n – m = 9 – 3 = 6
F= 12, Fкрит. = 5,143 при α = 0,05
- Делаем вывод о наличии статистически значимых отличий между группами:
так как наше значение F больше критического значения при заданном количестве наблюдений и количестве групп, иными словами наша дисперсия между группами вносит больший вклад в любую сумму дисперсий, чем таковая внутри самих групп.
Возраст влияет на длительность госпитализации после холецистектомии.
[1] Sum of squares between groups
[2] Sum of squares within groups
[3]MSBG — Средний квадрат отклонения между группами и MSWG — Средний квадрат отклонения внутри групп
Источник
Дисперсионный анализ: соединение теории и практики
Дисперсионный анализ: основные понятия
Для чего применяется дисперсионный анализ? Цель дисперсионного анализа — исследование наличия или отсутствия существенного влияния какого-либо качественного или количественного фактора на изменения исследуемого результативного признака. Для этого фактор, предположительно имеющий или не имеющий существенного влияния, разделяют на классы градации (говоря иначе, группы) и выясняют, одинаково ли влияние фактора путём исследования значимости между средними в наборах данных, соответствующих градациям фактора. Примеры: исследуется зависимость прибыли предприятия от типа используемого сырья (тогда классы градации — типы сырья), зависимость себестоимости выпуска единицы продукции от величины подразделения предприятия (тогда классы градации — характеристики величины подразделения: большой, средний, малый).
Минимальное число классов градации (групп) — два. Классы градации могут быть качественными либо количественными.
Дисперсионный анализ — почти универсальный метод проверки различий в группах, поскольку применяется как в технических науках и маркетологии, так и в исследованиях поведения человека.
Почему дисперсионный анализ называется дисперсионным? При дисперсионном анализе исследуется отношение двух дисперсий. Дисперсия, как мы знаем — характеристика рассеивания данных вокруг среднего значения. Первая — дисперсия, объяснённая влиянием фактора, которая характеризует рассеивание значений между градациями фактора (группами) вокруг средней всех данных. Вторая — необъяснённая дисперсия, которая характеризует рассеивание данных внутри градаций (групп) вокруг средних значений самих групп. Первую дисперсию можно назвать межгрупповой, а вторую — внутригрупповой. Отношение этих дисперсий называется фактическим отношением Фишера и сравнивается с критическим значением отношения Фишера. Если фактическое отношение Фишера больше критического, то средние классов градации отличаются друг от друга и исследуемый фактор существенно влияет на изменение данных. Если меньше, то средние классов градации не отличаются друг от друга и фактор не имеет существенного влияния.
Как формулируются, принимаются и отвергаются гипотезы при дисперсионном анализе? При дисперсионном анализе определяют удельный вес суммарного воздействия одного или нескольких факторов. Существенность влияния фактора определяется путём проверки гипотез:
- H 0 : μ 1 = μ 2 = . = μ a , где a — число классов градации — все классы градации имеют одно значение средних,
- H 1 : не все μ i равны — не все классы градации имеют одно значение средних.
Если влияние фактора не существенно, то несущественна и разница между классами градации этого фактора и в ходе дисперсионного анализа нулевая гипотеза H 0 не отвергается. Если влияние фактора существенно, то нулевая гипотеза H 0 отвергается: не все классы градации имеют одно и то же среднее значение, то есть среди возможных разниц между классами градации одна или несколько являются существенными.
Ещё некоторые понятия дисперсионного анализа. Статистическим комплексом в дисперсионном анализе называется таблица эмпирических данных. Если во всех классах градаций одинаковое число вариантов, то статистический комплекс называется однородным (гомогенным), если число вариантов разное — разнородным (гетерогенным).
В зависимости от числа оцениваемых факторов различают однофакторный, двухфакторый и многофакторный дисперсионный анализ.
Однофакторный дисперсионный анализ: суть метода, формулы, примеры
Суть метода, формулы
Однофакторный дисперсионный анализ основан на том, что сумму квадратов отклонений статистического комплекса возможно разделить на компоненты:
SS — общая сумма квадратов отклонений,
SS a — объяснённая влиянием фактора a сумма квадратов отклонений,
SS e — необъяснённая сумма квадратов отклонений или сумма квадратов отклонений ошибки.
Если через n i обозначить число вариантов в каждом классе градации (группе) и a — общее число градаций фактора (групп), то  — общее число наблюдений и можно получить следующие формулы:
— общее число наблюдений и можно получить следующие формулы:
общее число квадратов отклонений:  ,
,
объяснённая влиянием фактора a сумма квадратов отклонений:  ,
,
необъяснённая сумма квадратов отклонений или сумма квадратов отклонений ошибки:  ,
,
 — общее среднее наблюдений,
— общее среднее наблюдений,
 — среднее наблюдений в каждой градации фактора (группе).
— среднее наблюдений в каждой градации фактора (группе).

где  — дисперсия градации фактора (группы).
— дисперсия градации фактора (группы).
Чтобы провести однофакторный дисперсионный анализ данных статистического комплекса, нужно найти фактическое отношение Фишера — отношение дисперсии, объяснённой влиянием фактора (межрупповой), и необъяснённой дисперсии (внутригрупповой):

и сравнить его с критическим значением Фишера  .
.
Дисперсии рассчитываются следующим образом:
 — объяснённая дисперсия,
— объяснённая дисперсия,
 — необъяснённая дисперсия,
— необъяснённая дисперсия,
v a = a − 1 — число степеней свободы объяснённой дисперсии,
v e = n − a — число степеней свободы необъяснённой дисперсии,
v = n − 1 — общее число степеней свободы.
Критическое значение отношения Фишера с определёнными значениями уровня значимости и степеней свободы можно найти в статистических таблицах или рассчитать с помощью функции MS Excel F.ОБР (рисунок ниже, для его увеличения щёлкнуть по нему левой кнопкой мыши).

Функция требует ввести следующие данные:
Вероятность — уровень значимости α ,
Степени_свободы1 — число степеней свободы объяснённой дисперсии v a ,
Степени_свободы2 — число степеней свободы необъяснённой дисперсии v e .
Если фактическое значение отношения Фишера больше критического ( ), то нулевая гипотеза отклоняется с уровнем значимости α . Это означает, что фактор существенно влияет на изменение данных и данные зависимы от фактора с вероятностью P = 1 − α .
), то нулевая гипотеза отклоняется с уровнем значимости α . Это означает, что фактор существенно влияет на изменение данных и данные зависимы от фактора с вероятностью P = 1 − α .
Если фактическое значение отношения Фишера меньше критического ( ), то нулевая гипотеза не может быть отклонена с уровнем значимости α . Это означает, что фактор не оказывает существенного влияния на данные с вероятностью P = 1 − α .
), то нулевая гипотеза не может быть отклонена с уровнем значимости α . Это означает, что фактор не оказывает существенного влияния на данные с вероятностью P = 1 − α .
Однофакторный дисперсионный анализ: примеры
Пример 1. Требуется выяснить, влияет ли тип используемого сырья на прибыль предприятия. В шести классах градации (группах) фактора (1-й тип, 2-й тип и т.д.) собраны данные о прибыли от производства 1000 единиц продукции в миллионах рублей в течении 4 лет.
| Тип сырья | 2014 | 2015 | 2016 | 2017 |
| 1-й | 7,21 | 7,55 | 7,29 | 7,6 |
| 2-й | 7,89 | 8,27 | 7,39 | 8,18 |
| 3-й | 7,25 | 7,01 | 7,37 | 7,53 |
| 4-й | 7,75 | 7,41 | 7,27 | 7,42 |
| 5-й | 7,7 | 8,28 | 8,55 | 8,6 |
| 6-й | 7,56 | 8,05 | 8,07 | 7,84 |
Среднее  | Дисперсия  |
| 7,413 | 0,0367 |
| 7,933 | 0,1571 |
| 7,290 | 0,0480 |
| 7,463 | 0,0414 |
| 8,283 | 0,1706 |
| 7,880 | 0,0563 |
Число классов градации фактора (групп) a = 6 и в каждом классе (группе) n i = 4 наблюдения. Общее число наблюдений n = 24 .
Числа степеней свободы:
Вычислим суммы квадратов отклонений:





 .
.
Вычислим фактическое отношение Фишера:
 .
.
Критическое значение отношения Фишера:

Так как фактическое отношение Фишера больше критического:
 ,
,
с уровнем значимости α = 0,05 делаем вывод, что прибыль предприятия в зависимости от вида сырья, использованного в производстве, существенно отличается.
Или, что то же самое, отвергаем основную гипотезу о равенстве средних во всех классах градации фактора (группах).
В только что рассмотренном примере в каждом классе градации фактора было одинаковое число вариантов. Но, как говорилось во вступительной части, число вариантов может быть и разным. И это ни в коей мере не усложняет процедуру дисперсионного анализа. Таков следующий пример.
Пример 2. Требуется выяснить, существует ли зависимость себестоимости выпуска единицы продукции от величины подразделения предприятия. Фактор (величина подразделения) делится на три класса градации (группы): малые, средние, большие. Обобщены соответствующие этим группам данные о себестоимости выпуска единицы одного и того же вида продукции за некоторый период.
| малый | средний | большой | |
| 48 | 47 | 46 | |
| 50 | 61 | 57 | |
| 63 | 63 | 57 | |
| 72 | 47 | 55 | |
| 43 | 32 | ||
| 59 | 59 | ||
| 58 | |||
| Среднее | 58,6 | 54,0 | 51,0 |
| Дисперсия | 128,25 | 65,00 | 107,60 |
Число классов градации фактора (групп) a = 3 , число наблюдений в классах (группах) n 1 = 4 , n 2 = 7 , n 3 = 6 . Общее число наблюдений n = 17 .
Числа степеней свободы:
Вычислим суммы квадратов отклонений:




 ,
,
 .
.
Вычислим фактическое отношение Фишера:
 .
.
Критическое значение отношения Фишера:
 .
.
Так как фактическое значение отношения Фишера меньше критического:  , делаем вывод, что размер подразделения предприятия не оказывает существенного влияния на себестоимость выпуска продукции.
, делаем вывод, что размер подразделения предприятия не оказывает существенного влияния на себестоимость выпуска продукции.
Или, что то же самое, с вероятностью 95% принимаем основную гипотезу о том, что средняя себестоимость выпуска единицы одной и той же продукции в малых, средних и крупных подразделениях предприятия существенно не различается.
Однофакторный дисперсионный анализа в MS Excel
Однофакторный дисперсионный анализ можно провести с помощью процедуры MS Excel Однофакторный дисперсионный анализ. Используем его для анализа данных о связи типа используемого сырья и прибыли предприятия из примера 1.
В меню MS Excel выполняем команду Сервис/Анализ данных и выбираем средство анализа Однофакторный дисперсионный анализ.
В окошке Входной интервал указываем область данных (в нашем случае это $A$2:$E$7). Указываем, как сгруппирован фактор — по столбцам или по строкам (в нашем случае по строкам). Если первый столбец содержит названия классов фактора, помечаем галочкой окно Метки в первом столбце. В окне Альфа указываем уровень значимости α = 0,05 .


В результате действия процедуры выводятся две таблицы. Первая таблица — Итоги. В ней содержатся данные обо всех классах градации фактора: число наблюдений, суммарное значение, среднее значение и дисперсия.

Во второй таблице — Дисперсионный анализ — содержатся данные о величинах для фактора между группами и внутри групп и итоговых. Это сумма квадратов отклонений (SS), число степеней свободы (df), дисперсия (MS). В последних трёх столбцах — фактическое значение отношения Фишера(F), p-уровень (P-value) и критическое значение отношения Фишера (F crit).
| Дисперсионный анализ | ||
| Источник вариации | SS | df |
| Между группами | 2,9293 | 5 |
| Внутри групп | 1,5303 | 18 |
| Итого | 4,4596 | 23 |
| MS | F | P-value | F crit |
| 0,58585 | 6,891119 | 0,000936 | 2,77285 |
| 0,085017 |
Так как фактическое значение отношения Фишера (6,89) больше критического (2,77), с вероятностью 95% отклоняем нулевую гипотезу о равенстве средних производительности при использовании всех типов сырья, то есть делаем вывод о том, что тип используемого сырья влияет на прибыль предприятия.
Двухфакторный дисперсионный анализ без повторений: суть метода, формулы, пример
Двухфакторный дисперсионный анализ применяется для того, чтобы проверить возможную зависимость результативного признака от двух факторов — A и B. Тогда a — число градаций фактора A и b — число градаций фактора B. В статистическом комплексе сумма квадратов остатков разделяется на три компоненты:
 — общая сумма квадратов отклонений,
— общая сумма квадратов отклонений,
 — объяснённая влиянием фактора A сумма квадратов отклонений,
— объяснённая влиянием фактора A сумма квадратов отклонений,
 — объяснённая влиянием фактора B сумма квадратов отклонений,
— объяснённая влиянием фактора B сумма квадратов отклонений,
 — необъяснённая сумма квадратов отклонений или сумма квадратов отклонений ошибки,
— необъяснённая сумма квадратов отклонений или сумма квадратов отклонений ошибки,
 — общее среднее наблюдений,
— общее среднее наблюдений,
 — среднее наблюдений в каждой градации фактора A ,
— среднее наблюдений в каждой градации фактора A ,
 — среднее число наблюдений в каждой градации фактора B .
— среднее число наблюдений в каждой градации фактора B .
Дисперсии вычисляются следующим образом:
 — дисперсия, объяснённая влиянием фактора A ,
— дисперсия, объяснённая влиянием фактора A ,
 — дисперсия, объяснённая влиянием фактора B ,
— дисперсия, объяснённая влиянием фактора B ,
 — необъяснённая дисперсия или дисперсия ошибки,
— необъяснённая дисперсия или дисперсия ошибки,
v a = a − 1 — число степеней свободы дисперсии, объяснённой влиянием фактора A ,
v b = b − 1 — число степеней свободы дисперсии, объяснённой влиянием фактора B ,
v e = (a − 1)(b − 1) — число степеней свободы необъяснённой дисперсии или дисперсии ошибки,
v = ab − 1 — общее число степеней свободы.
Если факторы не зависят друг от друга, то для определения существенности факторов выдвигаются две нулевые гипотезы и соответствующие альтернативные гипотезы:
H 1 : не все μ iA равны;
H 1 : не все μ iB равны.
Чтобы определить влияние фактора A , нужно фактическое отношение Фишера  сравнить с критическим отношением Фишера
сравнить с критическим отношением Фишера  .
.
Чтобы определить влияние фактора B , нужно фактическое отношение Фишера  сравнить с критическим отношением Фишера
сравнить с критическим отношением Фишера  .
.
Если фактическое отношение Фишера больше критического отношения Фишера, то следует отклонить нулевую гипотезу с уровнем значимости α . Это означает, что фактор существенно влияет на данные: данные зависят от фактора с вероятностью P = 1 − α .
Если фактическое отношение Фишера меньше критического отношения Фишера, то следует принять нулевую гипотезу с уровнем значимости α . Это означает, что фактор не оказывает существенного влияния на данные с вероятностью P = 1 − α .
Двухфакторный дисперсионный анализ без повторений: пример
Пример 3. Дана информация о среднем потреблении топлива на 100 километров в литрах в зависимости от объёма двигателя и вида топлива.
| Бензин со свинцом | |
| 1001-1500 см³ | 9,3 |
| 1501-2000 см³ | 9,4 |
| Более 2000 см³ | 12,6 |
Среднее  | 10,42 |
| Бензин без свинца | Дизельное топливо | Среднее  |
| 8,9 | 6,5 | 8,23 |
| 9,1 | 7,1 | 8,53 |
| 9,8 | 8,0 | 10,13 |
| 9,27 | 7,2 |
Требуется проверить, зависит ли потребление топлива от объёма двигателя и вида топлива.
Решение. Для фактора A число классов градации a = 3 , для фактора B число классов градации b = 3 .
Вычисляем суммы квадратов отклонений:
 ,
,
 ,
,
 ,
,
 .
.
 ,
,
 ,
,
 .
.
Фактическое отношение Фишера для фактора A  , критическое значение отношения Фишера:
, критическое значение отношения Фишера:  . Так как фактическое отношение Фишера меньше критического, с вероятностью 95% принимаем гипотезу о том, что объём двигателя не влияет на потребление топлива. Однако, если мы выбираем уровень значимости α = 0,1 , то фактическое значение отношения Фишера
. Так как фактическое отношение Фишера меньше критического, с вероятностью 95% принимаем гипотезу о том, что объём двигателя не влияет на потребление топлива. Однако, если мы выбираем уровень значимости α = 0,1 , то фактическое значение отношения Фишера  и тогда с вероятностью 95% можем принять, что объём двигателя влияет на потребление топлива.
и тогда с вероятностью 95% можем принять, что объём двигателя влияет на потребление топлива.
Фактическое отношение Фишера для фактора B  , критическое значение отношения Фишера:
, критическое значение отношения Фишера:  . Так как фактическое отношение Фишера больше критического значения отношения Фишера, с вероятностью 95% принимаем, что вид топлива влияет на его потребление.
. Так как фактическое отношение Фишера больше критического значения отношения Фишера, с вероятностью 95% принимаем, что вид топлива влияет на его потребление.

Двухфакторный дисперсионный анализ без повторений в MS Excel
Двухфакторный дисперсионный анализ без повторений можно провести с помощью процедуры MS Excel Двухфакторный дисперсионный анализ без повторений. Используем его для анализа данных о связи типа вида топлива и его потребления из примера 3.
В меню MS Excel выполняем команду Сервис/Анализ данных и выбираем средство анализа Двухфакторный дисперсионный анализ без повторений.
Заполняем данные также, как и в случае с однофакторным дисперсионным анализом.

В результате действия процедуры выводятся две таблицы. Первая таблица — Итоги. В ней содержатся данные обо всех классах градации фактора: число наблюдений, суммарное значение, среднее значение и дисперсия.

Во второй таблице — Дисперсионный анализ — содержатся данные об источниках вариации: рассеивании между строками, рассеивании между столбцами, рассеивании ошибки, общем рассеивании, сумма квадратов отклонений (SS), число степеней свободы (df), дисперсия (MS). В последних трёх столбцах — фактическое значение отношения Фишера(F), p-уровень (P-value) и критическое значение отношения Фишера (F crit).
| Дисперсионный анализ | ||
| Источник вариации | SS | df |
| Строки | 6,26 | 2 |
| Столбцы | 16,08667 | 2 |
| Погрешность | 2,373333 | 4 |
| Итого | 24,72 | 8 |
| MS | F | P-value | F crit |
| 3,13 | 5,275281 | 0,075572 | 6,94476 |
| 8,043333 | 13,55618 | 0,016529 | 6,944276 |
| 0,593333 |
Фактор A (объём двигателя) сгурппирован в строках. Так как фактическое отношение Фишера 5,28 меньше критического 6,94, с вероятностью 95% принимаем, что потребление топлива не зависит от объёма двигателя.
Фактор B (вид топлива) сгруппирован в столбцах. Фактическое отношение Фишера 13,56 больше критического 6,94, поэтому с вероятностью 95% принимаем, что потребление топлива зависит от его вида.
Двухфакторный дисперсионный анализ с повторениями: суть метода, формулы, пример
Двухфакторный дисперсионный анализ с повторениями применяется для того, чтобы проверить не только возможную зависимость результативного признака от двух факторов — A и B, но и возможное взаимодействие факторов A и B. Тогда a — число градаций фактора A и b — число градаций фактора B, r — число повторений. В статистическом комплексе сумма квадратов остатков разделяется на четыре компоненты:
 — общая сумма квадратов отклонений,
— общая сумма квадратов отклонений,
 — объяснённая влиянием фактора A сумма квадратов отклонений,
— объяснённая влиянием фактора A сумма квадратов отклонений,
 — объяснённая влиянием фактора B сумма квадратов отклонений,
— объяснённая влиянием фактора B сумма квадратов отклонений,
 — объяснённая влиянием взаимодействия факторов A и B сумма квадратов отклонений,
— объяснённая влиянием взаимодействия факторов A и B сумма квадратов отклонений,
 — необъяснённая сумма квадратов отклонений или сумма квадратов отклонений ошибки,
— необъяснённая сумма квадратов отклонений или сумма квадратов отклонений ошибки,
 — общее среднее наблюдений,
— общее среднее наблюдений,
 — среднее наблюдений в каждой градации фактора A ,
— среднее наблюдений в каждой градации фактора A ,
 — среднее число наблюдений в каждой градации фактора B ,
— среднее число наблюдений в каждой градации фактора B ,
 — среднее число наблюдений в каждой комбинации градаций факторов A и B ,
— среднее число наблюдений в каждой комбинации градаций факторов A и B ,
n = abr — общее число наблюдений.
Дисперсии вычисляются следующим образом:
— дисперсия, объяснённая влиянием фактора A ,
— дисперсия, объяснённая влиянием фактора B ,
 — дисперсия, объяснённая взаимодействием факторов A и B ,
— дисперсия, объяснённая взаимодействием факторов A и B ,
 — необъяснённая дисперсия или дисперсия ошибки,
— необъяснённая дисперсия или дисперсия ошибки,
v a = a − 1 — число степеней свободы дисперсии, объяснённой влиянием фактора A ,
v b = b − 1 — число степеней свободы дисперсии, объяснённой влиянием фактора B ,
v ab = (a − 1)(b − 1) — число степеней свободы дисперсии, объяснённой взаимодействием факторов A и B ,
v e = ab(r − 1) — число степеней свободы необъяснённой дисперсии или дисперсии ошибки,
v = abr − 1 — общее число степеней свободы.
Если факторы не зависят друг от друга, то для определения существенности факторов выдвигаются три нулевые гипотезы и соответствующие альтернативные гипотезы:
H 1 : не все μ iA равны;
H 1 : не все μ iB равны;
для взаимодействия факторов A и B :
Чтобы определить влияние фактора A , нужно фактическое отношение Фишера сравнить с критическим отношением Фишера .
Чтобы определить влияние фактора B , нужно фактическое отношение Фишера сравнить с критическим отношением Фишера .
Чтобы определить влияние взаимодействия факторов A и B , нужно фактическое отношение Фишера  сравнить с критическим отношением Фишера
сравнить с критическим отношением Фишера  .
.
Если фактическое отношение Фишера больше критического отношения Фишера, то следует отклонить нулевую гипотезу с уровнем значимости α . Это означает, что фактор существенно влияет на данные: данные зависят от фактора с вероятностью P = 1 − α .
Если фактическое отношение Фишера меньше критического отношения Фишера, то следует принять нулевую гипотезу с уровнем значимости α . Это означает, что фактор не оказывает существенного влияния на данные с вероятностью P = 1 − α .
Двухфакторный дисперсионный анализ с повторениями: пример
Пример 4. Торговое предприятие имеет три магазина — A , B и C . Проводятся две рекламные кампании. Требуется выяснить, зависят ли средние дневные доходы магазинов от двух рекламных кампаний. Для процедуры проверки случайно выбраны по 3 дня каждой рекламной кампании (то есть число повторений r = 3 ). Результаты обобщены в таблице:
| Рекламная кампания | Магазин A |
| Рекламная кампания 1 | 12,05 |
| 23,94 | |
| 14,63 | |
| Рекламная кампания 2 | 25,78 |
| 17,52 | |
| 18,45 | |
| Среднее | 18,73 |
| Магазин B | Магазин C | Среднее |
| 15,17 | 9,48 | 14,53 |
| 18,52 | 6,92 | |
| 19,57 | 10,47 | |
| 21,40 | 7,63 | 15,86 |
| 13,59 | 11,90 | |
| 20,57 | 5,92 | |
| 18,14 | 8,72 |  |
Факторы, подлежащие проверке: магазин ( A , B и C ) и рекламная кампания (1 и 2). Пусть эти факторы не зависят друг от друга.
Вычислим суммы квадратов отклонений:
Числа степеней свободы:
v = abr − 1 = 2 ⋅ 3 ⋅ 3 − 1 = 17 .
 ,
,
 ,
,
 ,
,
 .
.
Фактические отношения Фишера:
для фактора A : 
для фактора B : 
для взаимодействия факторов A и B :  .
.
Критические значения отношения Фишера:
для фактора A :  ,
,
для фактора B : 
для взаимодействия факторов A и B :  .
.
о влиянии фактора A : фактическое отношение Фишера меньше критического значения, следовательно, рекламная кампания существенно не влияет на дневные доходы магазина с вероятностью 95%,
о влиянии фактора B : фактическое отношение Фишера больше критического, следовательно, доходы существенно различаются между магазинами,
о взаимодействии факторов A и B : фактическое отношение Фишера меньше критического, следовательно, взаимодействие рекламной кампании и конкретного магазина не существенно.
Двухфакторный дисперсионный анализ с повторениями в MS Excel
Двухфакторный дисперсионный анализ с повторениями можно провести с помощью процедуры MS Excel Двухфакторный дисперсионный анализ с повторениями. Используем его для анализа данных о связи доходов магазина с выбором конкретного магазина и рекламной кампанией из примера 4.
В меню MS Excel выполняем команду Сервис/Анализ данных и выбираем средство анализа Двухфакторный дисперсионный анализ с повторениями.
Заполняем данные также, как и в случае с двухфакторным дисперсионным анализом без повторений, с тем дополнением, что в окне число строк для выборки нужно ввести число повторений.

В результате действия процедуры выводятся две таблицы. Первая таблица состоит из трёх частей: две первые соответствуют каждой из двух рекламных кампаний, третья содержит данные об обеих рекламных кампаниях. В столбцах таблицы содержится информация обо всех классах градации второго фактора — магазина: число наблюдений, суммарное значение, среднее значение и дисперсия.

Во второй таблице — данные о сумме квадратов отклонений (SS), числе степеней свободы (df), дисперсии (MS), фактическом значение отношения Фишера(F), p-уровне (P-value) и критическом значении отношения Фишера (F crit) для различных источниках вариации: двух факторах, которые даны в строках (выборка) и столбцах, взаимодействии факторов, ошибки (внутри) и суммарных показателях (итого).
| Дисперсионный анализ | ||
| Источник вариации | SS | df |
| Выборка | 8,013339 | 1 |
| Столбцы | 378,3808 | 2 |
| Взаимодействие | 13,8504 | 2 |
| Внутри | 192,2233 | 12 |
| Итого | 592,4681 | 17 |
| MS | F | P-value | F crit |
| 8,013339 | 0,500252 | 0,492897 | 4,747221 |
| 189,1904 | 11,81066 | 0,001462 | 3,88529 |
| 6,925272 | 0,432327 | 0,658717 | 3,88529 |
| 16,01861 |
Для фактора A фактическое отношение Фишера меньше критического значения, следовательно, рекламная кампания существенно не влияет на дневные доходы магазина с вероятностью 95%.
Для фактора B фактическое отношение Фишера больше критического, следовательно, с вероятностью 95% доходы существенно различаются между магазинами.
Для взаимодействия факторов A и B фактическое отношение Фишера меньше критического, следовательно, с вероятностью 95% взаимодействие рекламной кампании и конкретного магазина не существенно.
Источник


