- Расшифровка разговоров с клиентами: как работает речевая аналитика
- Что такое речевая аналитика
- Как работает речевая аналитика
- Система распознавания речи
- Тегирование разговора
- Две звуковые дорожки
- Какие данные приносит речевая аналитика
- Резюме
- Анализ разговора — Conversation analysis
- Содержание
- История
- Метод
- Основные конструкции
- Очередность организации
- Пары смежности
- Расширение последовательности
- Организация предпочтений
- Ремонт
- Формирование действия
- Транскрипция Джефферсона
- Контрасты с другими теориями
- Применение в других сферах
- Тематический указатель разговорной литературы
Расшифровка разговоров с клиентами: как работает речевая аналитика
![]()
Менеджеры по-разному общаются во время звонка. Талантливые ищут подход к клиенту: говорят доброжелательно, угадывают потребности, предлагают выгоду. Они закрывают много заявок на продажу. Но так умеют не все. Часть сотрудников плохо продаёт, отпугивает грубостью и невниманием.
Подключить речевую аналитику
Невозможно стоять за плечом каждого и следить, чтобы менеджер не сказал лишнего. Выборочно прослушивать записи разговоров тоже неэффективно — это не даёт полной картины работы. Менеджер может быть вежлив с десятью клиентами и сорваться на одиннадцатого.
Как быть в курсе всех разговоров с вашими клиентами, быстро находить проблемные разговоры и не тратить на это всё свободное время? Расскажем в этой статье.
Что такое речевая аналитика
Речевая аналитика — это инструмент, который распознаёт речь в аудиозаписях, переводит в текст и составляет отчёты о разговорах.
Система записывает каждый диалог с клиентом. Затем транскрибирует аудиозаписи — превращает звуки в текстовый файл, проводя распознавание речи онлайн. Вы видите полный текст разговора.
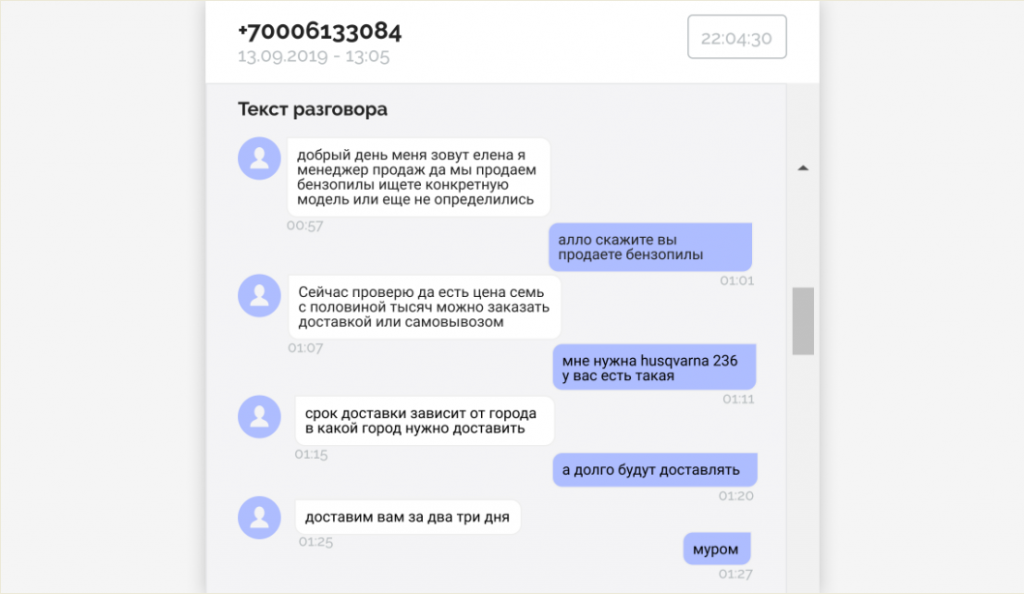
Сервис автоматически помечает важные моменты. Если оператор грубо говорит с клиентом, много молчит или перебивает, это отразится в отчёте.
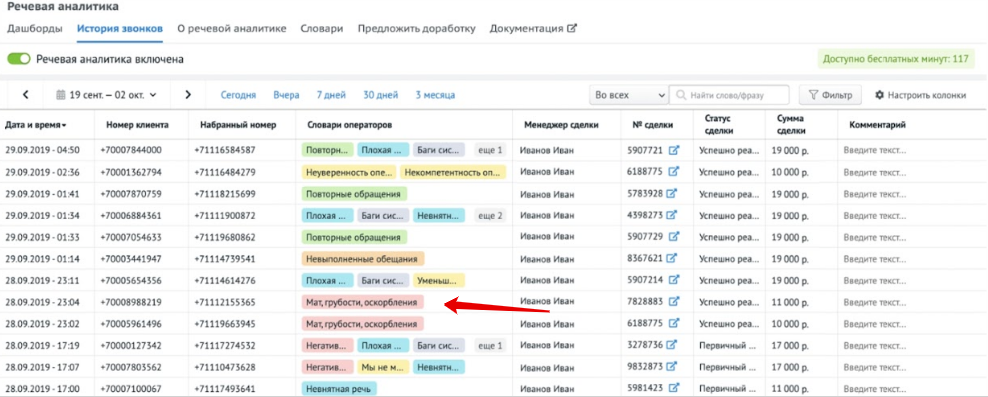
Компании используют такие отчёты, чтобы улучшить свою работу. Если сотрудник грубит, с ним проводят воспитательную беседу, если отходит от скриптов — напоминают о них.
Как работает речевая аналитика
Работа речевой аналитики основана на трёх механизмах: системе распознавания речи онлайн, тегировании разговора и разделении звуковых дорожек.
Система распознавания речи
Система производит распознавание слов, выделяя фонемы — минимальные смыслоразличительные единицы языка. То есть понимает, какое слово было произнесено, и отделяет слова друг от друга. Речь переводится в текст.
Лидеры рынка распознавания человека по голосу — Yandex и Google. Компании много лет работают над программой-распознавателем речи для поисковых систем и приложений. Они выпустили Yandex SpeechKit и Google Speech API — инструменты расшифровки разговора. Большинство систем речевой аналитики работает на их основе либо использует два инструмента сразу — повышает точность распознавания слов. Меньшинство компаний использует собственные алгоритмы распознавания языка онлайн.
Некоторые сервисы речевой аналитики работают «по-старинке» — с помощью людей. Операторы слушают разговоры и ставят на компьютере теги: отмечают, встретились ли определённые фразы. Ставят тег «Грубость» при словах «вы что, дурак» и тег «Рассказ об акции», если слышат «у нас в этом месяце проходит акция».
Машинный распознаватель речи эффективнее человеческого, и компании знают об этом. Нечестные сервисы могут обмануть — сказать, что используют алгоритмы, хотя на самом деле звонки слушают сотрудники. Но их выдаст скорость распознавания. Если компания не может обработать тысячу звонков в течение часа, она явно использует человеческий ресурс. Машинный центр распознавания речи справится с задачей играючи: алгоритм быстро работает с большими объёмами данных. Также у сервисов с человеческим распознаванием отличается цена: компании завышают прайс, чтобы оплачивать работу сотрудников.
Тегирование разговора
Распознанный текст анализируется на основе тегов — специально подобранных категорий слов. Каждый тег включает в себя набор фраз, которые помогут оценить работу сотрудника. Пример: тег «Слова-паразиты» может включать конструкции «как бы», «вот», «это самое».
Число тегов зависит от алгоритмов системы. Некоторые сервисы распознают мало параметров: целевое/нецелевое обращение, пол звонящего, нужная услуга. Другие сервисы подробно оценивают работу сотрудника и потребности клиента. В речевой аналитике Roistat данные анализируются по двадцати одному словарю — это пример глубокого тегирования.
Две звуковые дорожки
Разговор должен состоять из двух звуковых дорожек — речи клиента и речи оператора. Система видит участки, где дорожки разрываются (собеседники молчат) или налезают друг на друга. Большие разрывы фиксируются как «молчание», перехлёст дорожек — как «перебивание».
С одной звуковой дорожкой получилась бы каша: вы видите тег «Мат, грубости, оскорбления» и не знаете, попался сложный клиент или хамоватый сотрудник. Пришлось бы переслушивать большинство разговоров. С разведением дорожек работать легче: можно не обращать внимания на мат и перебивания от клиента, но отчитывать за них сотрудника.
Какие данные приносит речевая аналитика
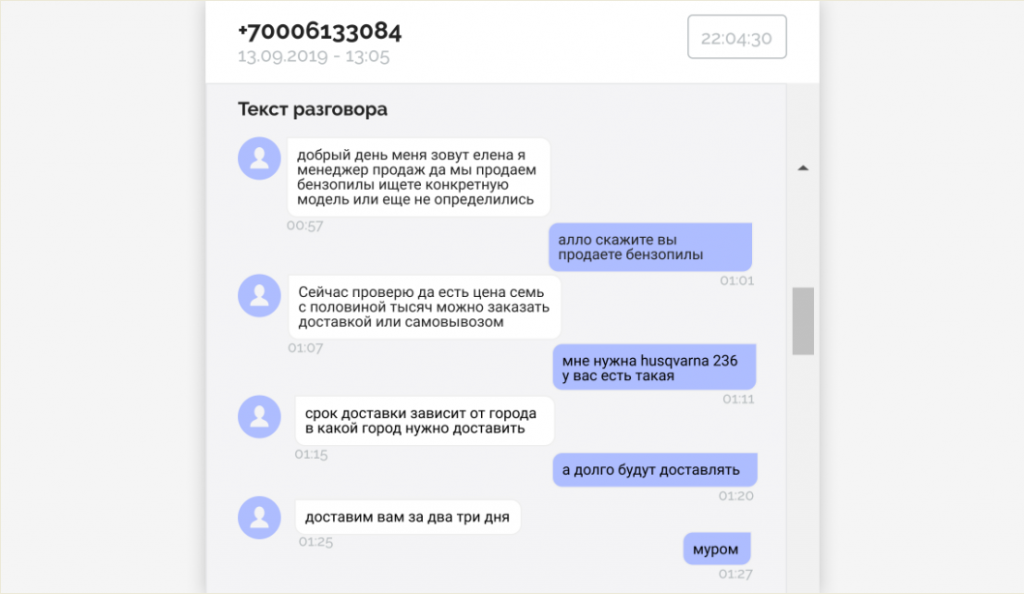
Речевая аналитика представляет расшифровку звонков в текстовом формате. Расшифровки можно оформить по-разному. В Roistat они похожи на переписку в социальной сети.

Подсвеченные места — фразы, которые относятся к тегам. По этим фразам легко найти важные места разговора.
Пример использования: сотрудник контроля качества видит, что у одного из операторов сработал тег «Мат, грубости оскорбления». Срабатывание тега ещё не означает проблемы. Возможно, оператор произнёс фразу невнятно, и система распознавания речи человека по голосу услышала в ней грубость.
Проверяющий открывает расшифровку разговора и смотрит на выделенную красным фразу. По остальному тексту видно, что оператор действительно ругался с клиентом и употребил мат. Сотрудник контроля качества идёт решать проблему.
В речевой аналитике Roistat для каждого тега составлен специальный словарь. Всего словарей — двадцать один. Каждый посвящён отдельной проблеме в общении менеджеров с клиентами.

Как только клиент или оператор произносит фразу из словаря, высвечивается тег. Если сотрудник ругнулся, в отчёте по звонку появится тег «Мат, грубости, оскорбления», если постоянно говорит «короче» — тег «Слова-паразиты».
Словари можно настроить под себя. В Roistat слово «тьфу» отсылает к тегу «недовольные восклицания». Но «тьфу» не всегда означает недовольство. Его и другие слова можно удалять из словаря и добавлять новые.

Также можно создать собственный словарь. В разговоре будут отмечены нужные вам фразы: рассказ оператора об акции, маркеры целевого звонка, слова из скрипта и другие.
Пример 1. Вы решили узнать, целевые или нецелевые лиды приводит отдел маркетинга. Вы создали словарь «целевые звонки» и занесли туда фразы заинтересованных клиентов: название компании, «хочу купить», «можно заказать» и другие. 90% разговоров получили тег «Целевые звонки». Вы похвалили отдел маркетинга за хорошую работу.
Пример 2. Операторы обязаны рассказывать клиентам об акции. Вы решили проверить, делают они это или нет. Вы добавили словарь «Акция» и вставили туда фразы из брифа: «акция», «при покупке», «две по цене трёх» и другие. Теперь у старательных операторов в отчёте будет стоять тег «Акция», а у ленивых — нет.
Интерфейс создания новых словарей Речевой аналтики Roistat:

Также речевая аналитика фиксирует динамику разговора. Система сопоставляет звуковые дорожки собеседников и фиксирует шесть элементов: молчание, залипания, перебивания, количество перебиваний в минуту, процент перебиваний и участки речи собеседников.
- Молчание — момент, когда во время звонка клиент и оператор одновременно молчат.
- Залипания — если клиент/оператор молчал больше пяти секунд после речи собеседника, то считается, что было залипание.
- Перебивания — одновременная речь менеджера и клиента.
- Процент перебиваний — общая длительность перебиваний в секундах (клиентом/оператором), делённая на общую длительность разговора в секундах.
- Количество перебиваний в минуту.
- Участки речи оператора/клиента.
Из элементов складываются метрики.

В результате речевая аналитика собирает полный отчёт о звонке: текст диалога, упоминания фраз из словарей и метрики:
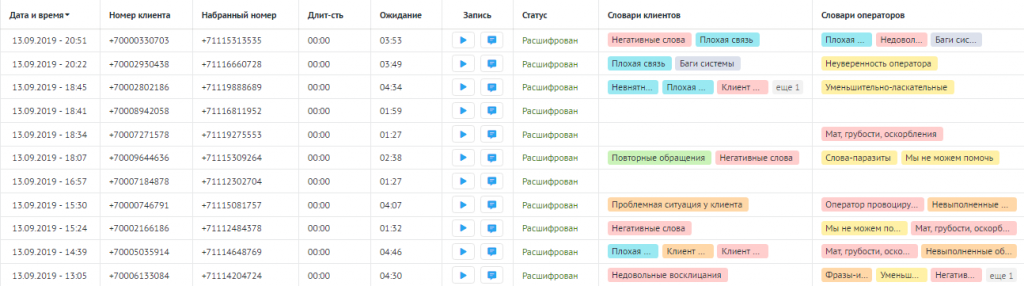
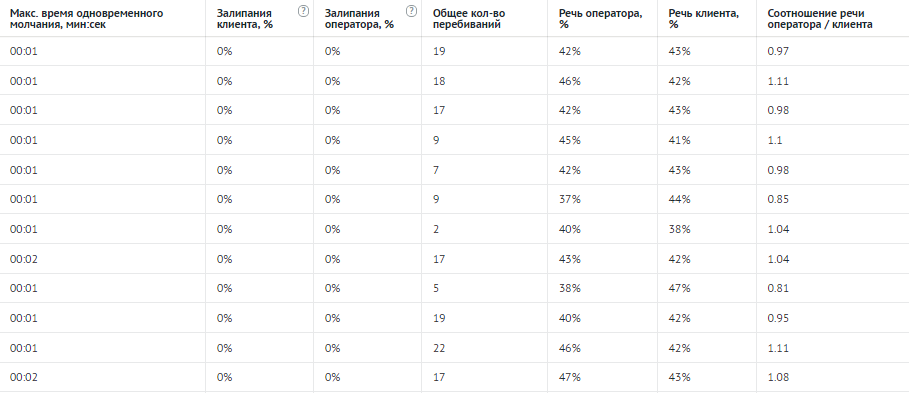
Эти данные отправляются в отделы продаж, маркетинга и контроля качества. Отделы используют новую информацию, чтобы повысить доход компании.
Резюме
Речевая аналитика — инструмент для аналитики звонков. Система предоставляет расшифровки записей разговоров и отмечает в них важные моменты.
Работает так: распознаёт человеческий голос и превращает в текст. Затем ищет в тексте фразы из словаря и помечает их. У клиента и оператора разные звуковые дорожки, поэтому их речь невозможно спутать. Анализируя наложения и расхождения звуковых дорожек, система высчитывает метрики разговора. Все данные речевая аналитика выдаёт в виде текстов и отчётов.
Восемь интересных вариантов применения речевой аналитики вы найдете в нашем следующем материале:
Подключить речевую аналитику
Будьте в курсе новостей

Присоединяйтесь к нашему каналу в Telegram или подпишитесь по E-mail





Маркетинговая платформа сквозной аналитики,
привлечения трафика, повышения конверсии и лояльности
Источник
Анализ разговора — Conversation analysis

Анализ разговора (CA) это подход к изучению социальное взаимодействие, охватывая как вербальное, так и невербальное поведение в ситуациях повседневной жизни. CA возникла как социологический метод, но с тех пор распространился на другие области. CA начала с упора на повседневную разговор, [1] но его методы впоследствии были адаптированы, чтобы охватить больше взаимодействий, ориентированных на задачи и учреждения, например, в кабинетах врачей, в судах, правоохранительных органах, на телефонах доверия, в образовательных учреждениях и в средствах массовой информации. Как следствие, термин «анализ разговора» стал употребляться неправильно, но он продолжал использоваться как термин для отличительного и успешного подхода к анализу социолингвистических взаимодействий.
Содержание
История
Вдохновленный Гарольд Гарфинкельс этнометодология [1] и Эрвинг Гоффманконцепция порядка взаимодействия, [2] СА была разработана в конце 1960-х — начале 1970-х годов главным образом социологами. Харви Сакс и его ближайшие соратники Эмануэль Шеглофф и Гейл Джефферсон. [3] Он отличается тем, что его основное внимание уделяется производству социальных действий в контексте последовательности действий, а не сообщений или предложений. Сегодня СА — признанный метод, используемый в социологии, антропологии, лингвистике, речевой коммуникации и психологии. Это особенно важно в интерактивная социолингвистика, анализ речи и дискурсивная психология.
Метод
Анализ разговора начинается с постановки проблемы, связанной с предварительной гипотезой. Данные, используемые в CA, находятся в форме видео- или аудиозаписей разговоров, собираемых с участием исследователей или без них, обычно с видеокамеры или другого записывающего устройства в помещении, где происходит разговор (например, гостиная, пикник. , или кабинет врача). Исследователи составляют подробные транскрипции из записей, содержащие как можно больше деталей (Jefferson 2004; Хепберн и Болден 2017; Мондада 2018). Эта транскрипция часто содержит дополнительную информацию о невербальная коммуникация и то, как люди говорят вещи. Транскрипция Джефферсона широко используемый метод транскрипции. [4]
После транскрипции исследователи выполняют индуктивный управляемый данными анализ стремясь найти повторяющиеся модели взаимодействия. На основе анализа исследователи определяют закономерности, правила или модели для описания этих закономерностей, улучшая, изменяя или заменяя исходные гипотезы. Хотя этот вид индуктивного анализа, основанный на совокупности экспонатов данных, является основой фундаментальной работы в СА, этот метод часто поддерживается статистическим анализом в приложениях СА для решения проблем в медицине и других областях.
В то время как анализ разговора обеспечивает метод анализа разговора, этот метод опирается на основную теорию о том, какие особенности разговора имеют значение, и значения, которые, вероятно, подразумеваются этими характеристиками. Кроме того, существует теория о том, как интерпретировать разговор. [5]
Основные конструкции
Очередность организации
![]()
Действия, из которых состоят разговоры, реализуются по очереди при разговоре, поэтому очередность является фундаментальной особенностью организации разговора. Анализ того, как работает очередность, сосредоточен на двух основных вопросах: i) каковы основные единицы очередей; и ii) как эти единицы распределяются между динамиками. Фундаментальный анализ очередности был описан в статье, широко известной как «Простейшая систематика» (Sacks, Schegloff and Jefferson 1974). [6]
1) Sacks et al. определить структурные единицы поворота (TCU) как фундаментальные строительные блоки поворотов. TCU могут быть предложениями, предложениями, фразами или отдельными словами, которые могут распознаваться как самостоятельные единицы в зависимости от контекста. Важнейшей особенностью TCU является то, что они проектируемы: то есть слушающий может распознать, что потребуется для завершения единицы. Именно такая проектируемость позволяет рассчитывать время за доли секунды, что характерно для обычных очередей людей. Точка завершения текущего TCU — это место перехода-поворота (или TRP).
2) В модели Сакса и др. Распределение единиц между говорящими осуществляется с помощью иерархически организованного набора правил. При любом заданном РВП:
i) Если текущий говорящий выбирает следующего, чтобы выступить в конце текущего TCU (по имени, взгляду или контекстуальным аспектам сказанного), выбранный говорящий имеет право и обязан говорить следующим. ii) Если текущий оратор не выбирает следующего оратора, другие потенциальные ораторы имеют право самостоятельно выбирать (очередь получает первый участник), и iii) если варианты i и ii не были реализованы, текущий оратор может продолжить другой ТЦУ. В конце этого TCU снова применяется система опций.
Обрисованная здесь модель очередности предназначена для учета широкого диапазона возможностей очередности, различного количества участников разговора и обстоятельств, при которых продолжительность очередей, разговоров и их тем никоим образом не предопределена. оговаривается заранее. Система внедряется участниками разговора без внешнего регулирования (администрируется абонентом) и на локальной единице за единицей. Описанная система, разработанная с учетом того факта, что большая часть разговора происходит без особой тишины или «мертвого времени», но также без значительного количества перекрывающихся разговоров, имеет множество последствий.
1) Он определяет тишину:
- Пауза: период молчания в TCU говорящего.
- Промежуток: период молчания между поворотами.
- Промежуток: период молчания, когда последовательность не выполняется: текущий говорящий прекращает говорить, не выбирает следующего говорящего и никто не выбирает сам. Промахи обычно связаны с визуальным или другим отсутствием взаимодействия между говорящими, даже если эти периоды короткие.
2) Он предусматривает, что ораторы, желающие провести длинный поворот, например, чтобы рассказать историю или описать важные новости, должны использовать какую-либо форму предисловия, чтобы получить добро, которое предусматривает, что другие воздерживаются от вмешательства в ходе рассказа ( Предисловие и связанное с ним разрешение составляют «предварительную последовательность» (Sacks 1974; Schegloff 2007)).
3) Он предусматривает, что разговоры не могут быть надлежащим образом завершены «простой остановкой», но требуют специальной последовательности завершения (Schegloff and Sacks 1973).
4) Он предусматривает учет определенных типов пробелов (после опции «текущий выбирает следующий»).
5) Он предусматривает использование специальных ресурсов в случае перекрытия разговоров (Schegloff 2000; Jefferson 2004b).
Модель также оставляет загадки, которые предстоит решить, например, касающиеся того, как границы TCU идентифицируются и проецируются, а также роль взгляда и ориентации тела в управлении очередностью. Он также устанавливает актуальность проблем для других дисциплин: например, время в доли секунды перехода череды создает когнитивную проблему « бутылочного горлышка », в которой потенциальные ораторы должны уделять внимание входящей речи, а также готовить свой собственный вклад — что-то, что требует большая нагрузка человеческих ресурсов обработки, которая может повлиять на структуру языков [Ссылки].
Модель очередности, описанная Саксом и др., Стала важной вехой в языковых науках, и это действительно самая цитируемая статья, когда-либо опубликованная в журнале Language (Joseph 2003). Однако он предназначен для моделирования очередности только в обычном разговоре, а не для взаимодействия в более специализированных институциональных средах, таких как собрания, суды, новостные интервью, слушания по медиации. У всех этих последних и многих других есть отличительные организации очередности, которые по-разному отходят от модели Сакса и др. Тем не менее принципиально важно, что мы не можем выполнять какие-либо социальные действия, не получив возможности поговорить, и, следовательно, эта очередность обеспечивает вездесущий фон, который формирует выполнение действия независимо от конкретной системы очередности в игре.
Пары смежности
Разговор обычно происходит в отзывчивых парах; однако пары могут быть разделены на последовательность ходов. Пары смежности делят типы высказываний на «части первой пары» и «части второй пары», чтобы сформировать «тип пары». Существует множество примеров пар смежности, включая вопросы-ответы, предложение-принятие / отказ и комплимент-ответ. (Schegloff & Sacks: 1973). [7]
Расширение последовательности
Расширение последовательности позволяет построить разговор, состоящий из более чем одной пары смежности, и понимать его как выполнение одного и того же основного действия, а различные дополнительные элементы — как выполнение интерактивной работы, связанной с выполняемым основным действием.
Расширение последовательности строится относительно базовой последовательности первая парная часть (FPP) и вторая парная часть (SPP), в котором осуществляется основное действие. Это может происходить до базового FPP, между базовым FPP и SPP и после базового SPP.
1. До расширения: пара смежности, которую можно понимать как предварительную к основному курсу действий. Общее предварительное раскрытие — это пара смежности «вызов-ответ», например, «Мэри?» / «Да?». Она является универсальной в том смысле, что не влияет на какие-либо конкретные типы базовой пары смежности, такие как запрос или предложение. . Существуют и другие типы предварительной последовательности, которые помогают подготовить собеседников к последующему речевому действию. Например, «Угадай что!» / «Что?» как предварительное объявление какого-либо рода или «Что вы делаете?» / «Ничего» как предварительное задание к приглашению или запросу.
2. Вставить расширение: пара смежности, которая находится между FPP и SPP базовой пары смежности. Вставить расширения прерывают текущую деятельность, но по-прежнему актуальны для этого действия. [8] Расширение вставки дает возможность второму говорящему, говорящему, который должен создать SPP, выполнять интерактивную работу, относящуюся к проектируемому SPP. Примером этого может быть типичный разговор между покупателем и продавцом:
Заказчик: Я хочу бутерброд с индейкой, пожалуйста. (База FPP) Сервер: белый или цельнозерновой? (Вставить FPP) Заказчик: цельнозерновой. (Вставить SPP) Сервер: Хорошо. (База СПП)
3. Пост-экспансия: поворот или пара смежности, которая идет после базовой пары смежности, но все еще привязана к ней. Есть два типа: минимальный и неминимальный. Минимальное расширение также называют последовательность закрывающих третей, потому что это один оборот после базовой SPP (следовательно, в третьих), который не ведет дальнейших разговоров, кроме их очереди (следовательно, закрытие). Примеры SCT включают «о», «я вижу», «хорошо» и т. Д.
4. Тишина: Молчание может происходить на протяжении всего речевого акта, но в каком контексте оно происходит, зависит, что означает молчание. Из-за тишины можно подразумевать три разных актива:
- Пауза: период молчания в очереди говорящего.
- Промежуток: период молчания между поворотами.
- Промежуток: период молчания, когда последовательность не выполняется: текущий говорящий прекращает говорить, не выбирает следующего говорящего и никто не выбирает сам. Промахи обычно связаны с визуальным или другим отсутствием взаимодействия между говорящими, даже если эти периоды короткие.
Организация предпочтений
CA может выявить структурные (то есть подтвержденные практикой) предпочтения в разговоре для одних типов действий (в рамках последовательности действий) по сравнению с другими. Например, ответные действия, которые соглашаются или принимают позицию, занимаемую первым действием, как правило, выполняются более прямолинейно и быстрее, чем действия, которые не согласны с этой позицией или отклоняются с ней (Pomerantz 1984; Davidson 1984). Первый называется немаркированной формой поворота, что означает, что повороту не предшествует тишина, и он не создается с задержками, смягчением последствий и расчетами. Последний называется формой отмеченного витка, который описывает поворот с противоположными характеристиками. Одним из следствий этого является то, что согласие и принятие продвигаются по сравнению с их альтернативами и с большей вероятностью будут результатом последовательности. Предварительные последовательности также являются компонентом организации предпочтений и вносят свой вклад в этот результат (Schegloff 2007).
Ремонт
Ремонтная организация описывает, как участники разговора справляются с проблемами в разговоре, слухе или понимании. Сегменты ремонта классифицируются по тому, кто инициирует ремонт (сам или другой), по тому, кто решает проблему (самостоятельно или другой), и по тому, как она разворачивается в ходе хода или последовательности ходов. Организация ремонта также является механизмом самовосстановления в социальном взаимодействии (Schegloff, Jefferson, and Sacks 1977). Участники разговора стремятся устранить источник неисправности, инициируя и предпочитая самовосстановление, говорящее об источнике неисправности, над другим ремонтом (Schegloff, Jefferson, and Sacks 1977). Инициирование самовосстановления может быть размещено в трех местах по отношению к источнику неисправности: в первый ход, в переходной области или в третьем (Шеглофф, Джефферсон и Сакс).
Формирование действия
Здесь основное внимание уделяется описанию практик, с помощью которых составляются и размещаются повороты в разговоре для реализации тех или иных действий.
Транскрипция Джефферсона
Гейл Джефферсон разработал систему транскрипции при работе с Харви Сакс. Выступающие обозначаются именем, за которым следует двоеточие, как обычно используется в сценариях. Он разработан для использования типографских соглашений, используемых в других местах. Система транскрипции указывает на перекрывающуюся речь, задержки между речью, высоту звука, громкость и скорость на основе исследований, показывающих, что эти функции имеют тенденцию передавать информацию. [4]
| Особенность | Используемый символ | пример |
|---|---|---|
| Очень тихо говорят | °°. °° | |
| Тихо говорят | °. ° | |
| Громко говорят | Заглавные буквы | |
| Падающие участки | . | |
| Неизменные высоты | _ | |
| Слегка повышающиеся участки | , | |
| Промежуточные высоты тона | ,? | |
| Восходящие передачи | ? | |
| Ударные слоги | Подчеркнутые буквы | |
| Отсутствие нормальных пауз | = | |
| Заметные паузы | (.) | |
| Паузы определенной продолжительности | (Продолжительность) | |
| Поспешная речь | > Основные размеры «
Контрасты с другими теориямиВ отличие от исследования, вдохновленного Ноам Хомский, который основан на различии между компетенцией и исполнением и не учитывает особенности реальной речи, анализ разговора изучает естественный разговор и показывает, что речевое взаимодействие систематически упорядочено во всех его аспектах (см. Sacks in Atkinson and Heritage 1984: 21– 27). В отличие от теории, развитой Джон Гумперц, CA утверждает, что можно анализировать разговор во взаимодействии, изучая только его записи (аудио для телефона, видео для одновременного взаимодействия). Исследователи ЦА не считают, что исследователю нужно консультироваться с участниками беседы или членами их речевое сообщество. Он отличается от анализ речи в фокусе и методе. (i) Он сосредоточен на процессах, вовлеченных в социальное взаимодействие, и не включает письменные тексты или более крупные социокультурные явления (например, «дискурсы» в смысле Фуко). (ii) Его метод, следуя инициативам Гарфинкеля и Гоффмана, направлен на определение методов и ресурсов, которые взаимодействующие участники использовать и полагаться на то, чтобы вносить интерактивный вклад и понимать вклад других. Таким образом, СА не предназначена и не нацелена на изучение производства взаимодействия с точки зрения, которая является внешней по отношению к собственным рассуждениям и пониманию участниками их обстоятельств и общения. Скорее цель состоит в том, чтобы смоделировать ресурсы и методы, с помощью которых производится это понимание. Рассматривая методы качественного анализа, Браун и Кларк выделяют тематический анализ из анализа разговоров и анализ речи, рассматривая тематический анализ как теоретический агнозит, в то время как анализ разговора и анализ дискурса считаются основанными на теориях. [9] Применение в других сферахВ последние годы CA использовалась исследователями в других областях, таких как феминизм и феминистская лингвистика, или используются в дополнение к другим теориям, таким как Анализ категоризации членства (MCA). MCA находился под влиянием работы над Харви Саксом и его работой над устройством категоризации членства (MCD). Сакс утверждает, что «категории членов» составляют часть центрального механизма организации, и разработал понятие MCD, чтобы объяснить, как категории могут быть слышны друг с другом носителями культуры. Его пример, взятый из детского сборника рассказов («Младенец плакал. Мама взяла его»), показывает, как носители той же культуры интерпретируют слово «мама» как мать ребенка. В свете этого, категории богаты выводами [10] — большая часть знаний, которыми обладают члены общества об обществе, хранится в терминах этих категорий. [11] Стокое далее утверждает, что практическая категоризация членов является частью этнометодологического описания текущего производства и реализации «фактов» о социальной жизни, включая гендерный анализ реальности членов, что делает СА совместимым с феминистскими исследованиями. [12] Тематический указатель разговорной литературыНиже приводится список важных явлений, выявленных в литературе по анализу разговоров, за которым следует краткое определение и ссылки на статьи, в которых названное явление исследуется эмпирически или теоретически. Статьи, в которых придуман термин для явления или которые представляют каноническую трактовку этого явления, выделены жирным шрифтом, те, которые в остальном имеют центральное отношение к явлению, выделены курсивом, а остальные статьи, которые в противном случае имеют целью внести значительный вклад в развитие этого явления. понимание явления. Источник |


