- АСИМПТОТИЧЕСКОЕ РАВЕНСТВО
- Значение слова «асимптотический»
- асимптоти́ческий
- Фразеологизмы и устойчивые сочетания
- Делаем Карту слов лучше вместе
- Синонимы к слову «асимптотический»
- Предложения со словом «асимптотический»
- Понятия, связанные со словом «асимптотический»
- Отправить комментарий
- Дополнительно
- Предложения со словом «асимптотический»
- Асимптотический анализ алгоритмов
АСИМПТОТИЧЕСКОЕ РАВЕНСТВО
Расстановка ударений: АСИМПТОТИ`ЧЕСКОЕ РА`ВЕНСТВО
АСИМПТОТИЧЕСКОЕ РАВЕНСТВО функций f(x) и g (х) при х → х0 означает, что в нек-рой окрестности точки х0 (за исключением, быть может, самой точки х0)
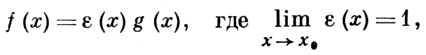
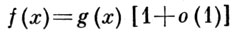
при х → х0 (х0 — конечная или бесконечная предельная точка множества, на к-ром определены рассматриваемые функции). Если функция g(x) не обращается в нуль в нек-рой окрестности точки х0, то это условие равносильно требованию
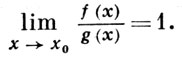
Иначе говоря, А. р. функций f(x) и g(x) при х → x0 означает в этом случае, что относительная погрешность приближенного равенства функций f(x) и g(x), т. е. величина [f(x) — g(x)]/g(х), g(x) ≠ 0, является бесконечно малой при х → х0 . А. р. функций содержательно для бесконечно малых и бесконечно больших функций. А. р. функций f(x) и g(x) обозначается f(x)
g(x) при х → х0 и обладает свойствами рефлексивности, симметричности и транзитивности. В силу этого совокупность бесконечно малых (бесконечно больших) при х → х0 функций распадается на классы эквивалентности бесконечно малых (бесконечно больших). Примером асимптотически равных функций (они наз. также эквивалентными) при х → х0 являются функции u(х), sin u(x), ln [1 + u(х)], е u(x) — 1, где lim u(х) = 0.
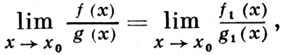
причем из существования каждого из написанных пределов следует существование другого. См. также Асимптотическое разложение функций, Асимптотическая формула.
- Математическая Энциклопедия. Т. 1 (А — Г). Ред. коллегия: И. М. Виноградов (глав ред) [и др.] — М., «Советская Энциклопедия», 1977, 1152 стб. с илл.
Источник
Значение слова «асимптотический»

асимптоти́ческий
1. матем. относящийся к асимптоте, то есть к такой прямой линии, к которой какая-либо кривая с бесконечной ветвью неограниченно приближается на бесконечно малое расстояние ◆ По сути, задача их сводилась к анализу кривой относительного познания в области ее асимптотического приближения к абсолютной истине. Аркадий Стругацкий, Борис Стругацкий, «Понедельник начинается в субботу», 1964 г. (цитата из НКРЯ)
Фразеологизмы и устойчивые сочетания
Делаем Карту слов лучше вместе
 Привет! Меня зовут Лампобот, я компьютерная программа, которая помогает делать Карту слов. Я отлично умею считать, но пока плохо понимаю, как устроен ваш мир. Помоги мне разобраться!
Привет! Меня зовут Лампобот, я компьютерная программа, которая помогает делать Карту слов. Я отлично умею считать, но пока плохо понимаю, как устроен ваш мир. Помоги мне разобраться!
Спасибо! Я стал чуточку лучше понимать мир эмоций.
Вопрос: повыдергать — это что-то нейтральное, положительное или отрицательное?
Синонимы к слову «асимптотический»
Предложения со словом «асимптотический»
- На протяжении всей книги вы будете встречать термин «асимптотический смысл», что означает возможный результат чего-либо, осуществлённого бесконечное число раз, когда вероятность приближается к определённости при увеличении количества попыток.
Понятия, связанные со словом «асимптотический»
Спектральные методы — это класс техник, используемых в прикладной математике для численного решения некоторых дифференциальных уравнений, возможно, вовлекая Быстрое преобразование Фурье. Идея заключается в переписи решения дифференциальных уравнений как суммы некоторых «базисных функций» (например, как ряды Фурье являются суммой синусоид), а затем выбрать коэффициенты в сумме, чтобы удовлетворить дифференциальному уравнению, насколько это возможно.
Отправить комментарий
Дополнительно
Предложения со словом «асимптотический»
На протяжении всей книги вы будете встречать термин «асимптотический смысл», что означает возможный результат чего-либо, осуществлённого бесконечное число раз, когда вероятность приближается к определённости при увеличении количества попыток.
Кто-то скажет, что философия – рациональное и систематическое формулирование и рассмотрение, надёжное и стабильное обоснование и понимание, экономичное и ясное объяснение и понимание высших жизненных целей, разъяснение эсхатологических основ исторического процесса, разгадка тайны бытия, направленность к экзистенциальному времени, к жизни без кавычек – словом, асимптотическое приближение к безусловному – абсолюту, истине, красоте, добру; другие же убеждены, что её цель – онтологически и аксиологически невинная, но глубокая мыслительная игра для любознательных и праздных.
Курс нелинейных колебаний – когда начал заниматься асимптотическими методами нелинейной механики.
Источник
Асимптотический анализ алгоритмов
Прежде чем приступать к обзору асимптотического анализа алгоритмов, хочу сказать пару слов о том, в каких случаях написанное здесь будет актуальным. Наверное многие программисты читая эти строки, думают про себя о том, что они всю жизнь прекрасно обходились без всего этого и конечно же в этих словах есть доля правды, но если встанет вопрос о доказательстве эффективности или наоборот неэффективности какого-либо кода, то без формального анализа уже не обойтись, а в серьезных проектах, такая потребность возникает регулярно.
В этой статье я попытаюсь простым и понятным языком объяснить, что же такое сложность алгоритмов и асимптотический анализ, а также возможности применения этого инструмента, для написания собственного эффективного кода. Конечно, в одном коротком посте не возможно охватить полностью такую обширную тему даже на поверхностном уровне, которого я стремился придерживаться, поэтому если то, что здесь написано вам понравится, я с удовольствием продолжу публикации на эту тему.
Во многих работах описывающих те или иные алгоритмы, часто можно встретить обозначения типа:
O(g(n)), Ω(g(n)), Θ(g(n)).
Давайте разбермся, что же это такое, но сначала я перечислю основные классы сложности применяемые при анализе:
f(n) = O(1) константа
f(n) = O(log(n)) логарифмический рост
f(n) = O(n) линейный рост
f(n) = O(n*log(n)) квазилинейный рост
f(n) = O(n^m) полиномиальный рост
f(n) = O(2^n) экспоненциальный рост
Если раньше вы не встречались с подобными обозначениями, не переживайте, после прочтения этой статьи, все станет намного понятнее.
А начнем мы с символа O.
Сначала приведу формальное определение:
(1.1) Запись вида f(n) = O(g(n)) означает, что ф-ия f(n) возрастает медленнее чем ф-ия g(n) при с = с1 и n = N, где c1 и N могут быть сколь угодно большими числами, т.е. При c = c1 и n >= N, c*g(n) >=f(n).
Таким образом O – означает верхнее ограничение сложности алгоритма.
Давайте теперь попробуем применить это знание на практике.
Возьмем известную любому программисту задачу сортировки. Допустим нам необходимо отсортировать массив чисел, размерностью 10 000 000 элементов. Договоримся рассматривать худший случай, при котором для выполнения алгоритма понадобится наибольшее количество итераций. Не долго думая, мы решаем применять сортировку пузырьком как самую простую с точки зрения реализации.
Сортировка пузырьком позволяет отсортировать массив любой размерности без дополнительных выделений памяти. Вроде бы все прекрасно и мы с чистой совестью начинаем писать код (для примеров здесь и далее будет использоваться язык Python).
def bubble_sort(arr):
. . for j in xrange(0, N — 1):
. . . . for i in xrange(0, N — 1):
. . . . . . if(arr[i] > arr[i+1]):
. . . . . . . . tmp = arr[i]
. . . . . . . . arr[i] = arr[i+1]
. . . . . . . . arr[i+1] = tmp
Я намерено не ввожу проверку на наличие хотябы одного обмена (которая кстати не сказывается на O — сложности алгоритма), ради упрощения понимания сути.
Взглянув на код, сразу же обращаем внимание на вложеный цикл. О чем нам это говорит? Я надеюсь, что читатель знаком с основами программирования на любом языке (кроме функциональных, в которых циклы отсутствуют как таковые, а повторения реализуются рекурсией) и наглядно представляет себе, что такое вложеные циклы и как они работают. В данном примере, внешний цикл выполняется ровно n = 10 000 000 (т.к. наш массив состоит из 10 000 000 элементов) и столько же раз выполняется внутренний цикл, из этого очевидно следует, что общее кол-во итераций будет порядка n^2. Т.е. кол-во итераций зависит от размерности входных данных как ф-ия от n^2. Теперь, зная сложность алгоритма, мы можем проверить, насколько хорошо он будет работать в нашем случае. Подставив цифры в формулу n^2 получаем ответ 10 000 000 * 10 000 000 = 10 000 000 000 0000 итераций.
Хммм, впечатляет… В цикле у нас 3 комманды, предположим, что на выполнение каждой из них требуется 5 единиц времени (с1 = 5), тогда общее кол-во времени затраченного на сортировку нашего массива будет равно 5*f(n^2) (синяя кривая на рис.1).

рис.1.
зеленая кривая соответствует графику ф-ии x^2 при c = 1, синия c = 5, красная c = 7
Здесь и далее на всех графиках ось абсцисс будет соответствовать размерности входных данных, а ось ординат кол-ву итераций необходимых для выполнения алгоритма.
Нас интересует только та часть координатной плоскости, которая соответствует значениям x большим 0, т.к. любой массив, по-определению, не может иметь отрицательный размер, поэтому, для удобства, уберем левые части графиков ф-ий, ограничившись лишь первой четвертью координатной плоскости.
рис.2.
зеленая кривая соответствует графику ф-ии x^2 при c = 1, синия c = 5, красная c = 7
Возьмем c2 = 7. Мы видим, что новая ф-ия растет быстрее предыдущей (красная кривая на рис.2). Из определения (1.1), делаем вывод, что при с2 = 7 и n >= 0, g(n) = 7*n^2 всегда больше или равна ф-ии f(n) = 5*n^2, следовательно наша программа имет сложность O(n^2).
Кто не до конца понял это объяснение, посмотрите на графики ф-ий и заметьте, что ф-ия отмеченная на нем красным, при n >= 0 всегда имеет большее значение по y, чем ф-ия отмеченная синим.
Теперь подумаем, хорошо ли это или плохо в нашем случае и можем ли мы заставить алгоритм работать эффективнее?
Как можно понять из графиков, приведенных на рис. 2, квадратичная ф-ия возрастает довольно быстро и при большом объеме входных данных, сортировка массива таким способом, может занять довольно длительное время, причем увеличение мощности процессора, будет сказываться лишь на коэффициенте c1, но сам алгоритм, по-прежнему будет принадлежать к классу алгоритмов с полиномиальной функцией роста O(n^2) (тут мы опять же используем определение (1.1) и подбираем такие c2 и N при которых с2*n^2 будет возрастать быстрее чем наша ф-ия c1*n^2 начиная с некоторого n >= N) и если в ближайшем будущем изобретут процессор, который будет сортировать наш массив всего за пару секунд, то при немного большем объеме входных данных, этот прирост в производительности будет полностью нивелирован кол-вом необходимых вычислений.
Таким же временным средством является решение реализовать алгоритм на низкоуровневом языке (например ассемблере), так как все, что мы сможем сделать – это, опять же, лишь немного уменьшить коэффициент c1 при этом все-равно оставаясь в классе сложности O(n^2).
А что будет, если вместо одноядерного процессора, мы будем использовать 4-х ядерный? На самом деле, результат изменится не сильно.
Разобьем наш массив на 4 части и каждую часть поручим выполнять отдельному ядру. Что мы получим? На сортировку каждой части понадобится ровно O((n / 4)^2). Так как все части сортируются одновременно, то этот результат и будет конечным временем сортировки четырех подмассивов, размерностью n/4. Возведем получившееся выражение в квадрат, получив таким образом сложность равную O(1/16*n^2 + n), где n — итерации необходимые на сортировку итогового массива полученного конкатенацией четырех готовых подмассивов.
Поскольку анализ у нас асимптотический, то при достаточно больших n, ф-ия n^2 будет вносить гораздо больший вклад в итоговый результат, чем n и поэтому мы спокойно можем им пренебречь, как наиболее медленно возрастающем членом, также за малозначимостью принебрегаем коэффициентом 1/16 (см. (1.1)), что в итоге дает нам все тоже O(n^2).
Мы приходим к неутишительному выводу о том, что увеличением числа процессоров, равно как и повышение их частоты, не дают существенного прироста при данном алгоритме сортировки.
Что же можно сделать в этой ситуации, чтобы радикально ускорить сортировку? Необходимо, чтобы в худшем случае сложность алгоритма была меньше чем O(n^2). Поразмыслив немного, мы решаем, что не плохо бы было, придумать такой алгоритм, сложность которого не превышает O(n), т.е. является линейной. Очевидно, что в случае O(n) скорость работы программы возрастет в N раз, так как вместо N^2 итераций, нам необходимо будет сделать всего лишь N. Прогнозируемый прирост скорости отлично виден на рис.3.
Серой прямой обозначена линейная сложность, а три кривых показывают сложность n^2 при различных коэффициентах c.
Но оказывается, что сделать сортировку со сложностью O(n) в общем случае просто не возможно (док-во)! Так на какую же сложность мы в лучшем случае можем расчитывать? Она равна O(n*log(n)), что является теоретически доказаным минимальным верхнем пределом для любого алгоритма сортировки основанного на сравнении элементов. Это конечно немного не то, чего мы ожидали получить, но все же это уже и не O(n^2). Осталось найти алгоритм сортировки удовлетворяющий нашим требованиям.
Покопавшись в интернете, видим, что им удовлетворяет «пирамидальная сортировка». Я не буду вдаваться в подробности алгоритма, желающие могут прочитать о нем самостоятельно на wiki, скажу только, что его сложность принадлежит классу O(n*log(n)) (т.е. максимально возможная производительность для сортировки), но при этом, он довольно труден в реализации.
Посмотрим на графики ниже и сравним скорости возрастания кол-ва вычислений для двух рассмотренных алгоритмов сортировки.
рис.4.
Фиолетовая кривая показывает алгоритм со сложностью n*log(n). Видно, что на больших n, пирамидальная сортировка существенно выигрывает у сортировки пузырьком при любом из трех опробованных нами коэффициентах, однако все-равно уступает гипотетической сортировке линейной сложности (серая прямая на графике).
В любом случае, даже на медленном компьютере она будет работать гораздо быстрее, чем «пузырек» на быстром.
Остается открытым вопрос, целесообразно ли всегда предпочитать пирамидальную сортировку сортировке пузырьком?
рис.5.
Как видно на рис.5, при малых n, различия между двумя алгоритмами достаточно малы и выгода от использования пирамидальной сортировки — совсем незначительна, а учитывая, что «пузырек» реализуется буквально 5-6 строчками кода, то при малых n, он действительно является более предпочтительным с точки зрения умственных и временных затрат на реализацию 🙂
В заключении, чтобы более наглядно продемонстрировать разницу между классами сложности, приведу такой пример:
Допустим у нас етсь ЭВМ 45-ти летней давности. В голове сразу всплывают мысли о больших шкафах, занимающих довольно-таки обширную площадь. Допустим, что каждая команда на такой машине выполняется примерно за 10 миллисек. С такой скоростью вычислений, имея алгоритм сложности O(n^2), на решение поставленой задачи уйдет оооочень много времени и от затеи придется отказаться как от невыполнимой за допустимое время, если же взять алгоритм со сложностью O(n*log(n)), то ситуация в корне изменится и на расчет уйдет не больше месяца.
Посчитаем, сколько именно займет сортировка массива в обоих случаях
сверх-неоптимальный алгоритм (бывает и такое, но редко):
O(2^n) = оооооочень медленно, вселенная умрет, прежде чем мы закончим наш расчет…
пузырек:
O(n^2) = 277777778 часов (классический “пузырек”)
пирамидальная сортировка:
O(n*log(n)) = 647 часов (то чего мы реально можем добиться, применяя пирамидальную сортировку)
фантастически-эффективный алгоритм:
O(n) = 2.7 часов (наш гипотетический алгоритм, сортирующий за линейное время)
и наконец:
O(log(n)) = оооооочень быстро, жаль, что чудес не бывает…
Два последних случая (хоть они и не возможны в реальности при сортировке данных) я привел лишь для того, чтобы читатель ощутил огромную разницу между алгоритмами различных классов сложности.
На последок хочу заметить, что буквой O обычно обозначают минимальный из классов сложности, которому соответствует данный алгоритм. К примеру, я мог бы сказать, что сложность сортировки пузырьком равна O(2^n) и теоретически это было бы абсолютно верным утверждением, однако на практике такая оценка была бы лишена смысла.
Источник


